 | Text provided under a Creative Commons Attribution license, CC-BY. All code is made available under the FSF-approved MIT license. (c) Kyle T. Mandli |
from __future__ import print_function
%matplotlib inline
import warnings
import matplotlib.pyplot as plt
import numpy
import sympy
sympy.init_printing()Root Finding and Optimization¶
Our goal in this section is to develop techniques to approximate the roots of a given function . That is find solutions such that . At first glance this may not seem like a meaningful exercise, however, this problem arises in a wide variety of circumstances.
For example, suppose that you are trying to find a solution to the equation
where is a real parameter. Simply rearranging, the expression can be rewritten in the form
Determining the roots of the function is now equivalent to determining the solution to the original expression. Unfortunately, a number of other issues arise. In particular, with non-linear equations, there may be multiple solutions, or no real solutions at all.
The task of approximating the roots of a function can be a deceptively difficult thing to do. For much of the treatment here we will ignore many details such as existence and uniqueness, but you should keep in mind that they are important considerations.
GOAL: For this section we will focus on multiple techniques for efficiently and accurately solving the fundamental problem for functions of a single variable.
Objectives¶
Understand the general rootfinding problem as
Understand the equivalent formulation as a fixed point problem
Understand fixed point iteration and its stability analysis
Understand definitions of convergence and order of convergence
Understand practical rootfinding algorithms and their convergence
Bisection
Newton’s method
Secant method
Hybrid methods and scipy.optimize routines (root_scalar)
Understand basic Optimization routines
Parabolic Interpolation
Golden Section Search
scipy.optimize routines (minimize_scalar and minimize)
Example: Future Time Annuity¶
Can I ever retire?
total value after years
is payment amount per compounding period
number of compounding periods per year
annual interest rate
number of years to retirement
Question:¶
For a fix monthly Payment , what does the minimum interest rate need to be so I can retire in 20 years with $1M.
Set .
def total_value(P, m, r, n):
"""Total value of portfolio given parameters
Based on following formula:
A = \frac{P}{(r / m)} \left[ \left(1 + \frac{r}{m} \right)^{m \cdot n}
- 1 \right ]
:Input:
- *P* (float) - Payment amount per compounding period
- *m* (int) - number of compounding periods per year
- *r* (float) - annual interest rate
- *n* (float) - number of years to retirement
:Returns:
(float) - total value of portfolio
"""
return P / (r / float(m)) * ((1.0 + r / float(m)) ** (float(m) * n) - 1.0)
P = 1500.0
m = 12
n = 20.0
r = numpy.linspace(0.05, 0.15, 100)
goal = 1e6
fig = plt.figure(figsize=(8, 6))
axes = fig.add_subplot(1, 1, 1)
axes.plot(r, total_value(P, m, r, 10), label="10 years", linewidth=2)
axes.plot(r, total_value(P, m, r, 15), label="15 years", linewidth=2)
axes.plot(r, total_value(P, m, r, n), label="20 years", linewidth=2)
axes.plot(r, numpy.ones(r.shape) * goal, "r--")
axes.set_xlabel("r (interest rate)", fontsize=16)
axes.set_ylabel("A (total value)", fontsize=16)
axes.set_title("When can I retire?", fontsize=18)
axes.ticklabel_format(axis="y", style="sci", scilimits=(-1, 1))
axes.set_xlim((r.min(), r.max()))
axes.set_ylim((total_value(P, m, r.min(), 10), total_value(P, m, r.max(), n)))
axes.legend(loc="best")
axes.grid()
plt.show()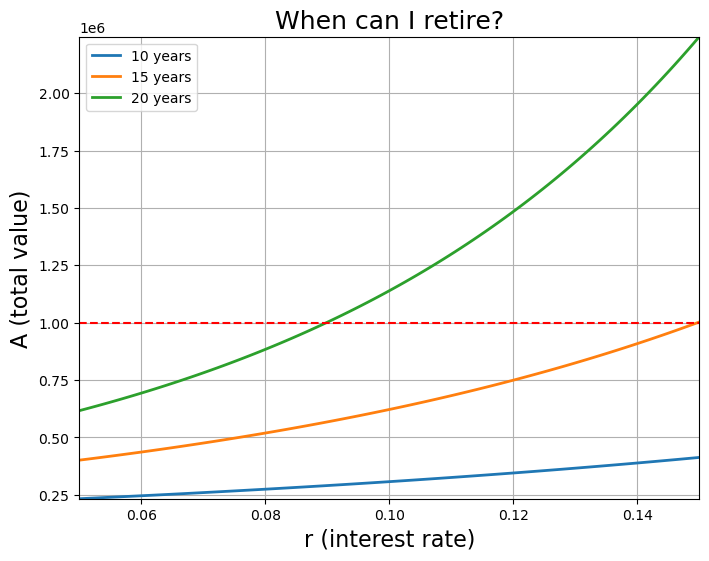
def g(P, m, r, n, A):
"""Reformulated minimization problem
Based on following formula:
g(r) = \frac{P \cdot m}{A} \left[ \left(1 + \frac{r}{m} \right)^{m \cdot n} - 1 \right ]
:Input:
- *P* (float) - Payment amount per compounding period
- *m* (int) - number of compounding periods per year
- *r* (float) - annual interest rate
- *n* (float) - number of years to retirement
- *A* (float) - total value after $n$ years
:Returns:
(float) - value of g(r)
"""
return P * m / A * ((1.0 + r / float(m)) ** (float(m) * n) - 1.0)
P = 1500.0
m = 12
n = 20.0
r = numpy.linspace(0.00, 0.1, 100)
goal = 1e6
fig = plt.figure(figsize=(16, 6))
axes = fig.add_subplot(1, 2, 1)
axes.plot(r, g(P, m, r, n, goal), label="$g(r)$")
axes.plot(r, r, "r--", label="$r$")
axes.set_xlabel("r (interest rate)", fontsize=16)
axes.set_ylabel("$g(r)$", fontsize=16)
axes.set_title("Minimum rate for a 20 year retirement?", fontsize=18)
axes.set_ylim([0, 0.12])
axes.ticklabel_format(axis="y", style="sci", scilimits=(-1, 1))
axes.set_xlim((0.00, 0.1))
axes.set_ylim((g(P, m, 0.00, n, goal), g(P, m, 0.1, n, goal)))
axes.legend(fontsize=14)
axes.grid()
axes = fig.add_subplot(1, 2, 2)
axes.plot(r, g(P, m, r, n, goal) - r, label="$g(r) - r$")
axes.plot(r, numpy.zeros(r.shape), "r--", label="$0$")
axes.set_xlabel("r (interest rate)", fontsize=16)
axes.set_ylabel("residual", fontsize=16)
axes.set_title("Minimum rate for a 20 year retirement?", fontsize=18)
axes.ticklabel_format(axis="y", style="sci", scilimits=(-1, 1))
axes.set_xlim((0.00, 0.1))
axes.legend(fontsize=14)
axes.grid()
plt.show()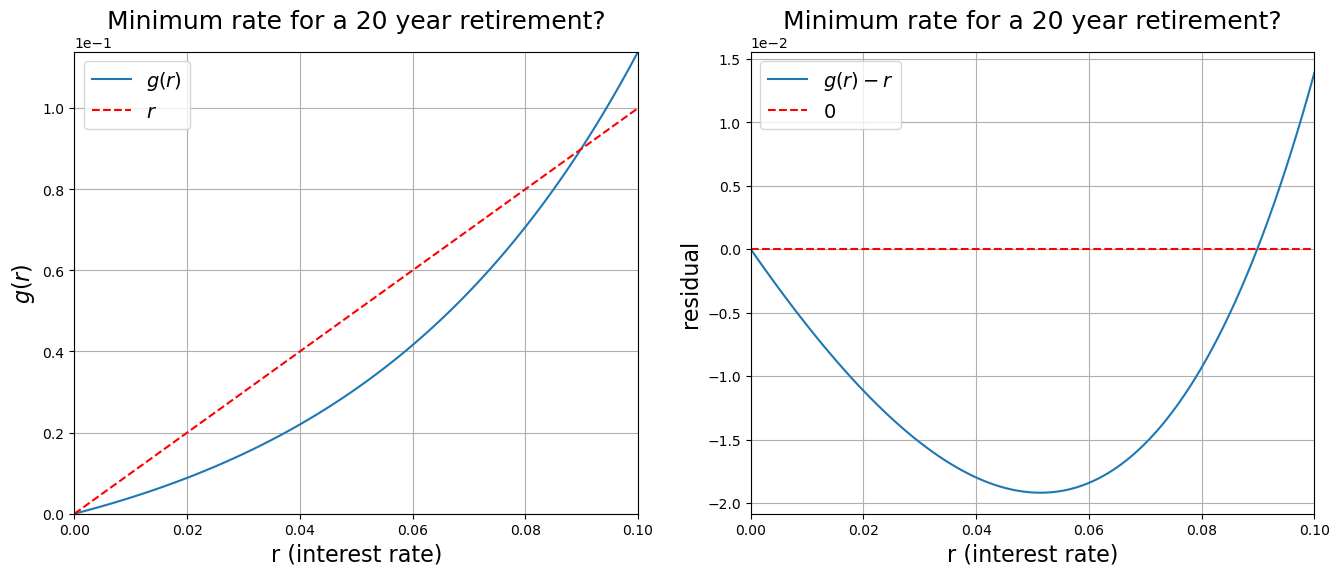
Question:¶
A single root clearly exists around . But how to find it?
One option might be to take a guess say and form the iterative scheme
and hope this converges as (or faster)
Easy enough to code¶
r = 0.088
K = 20
for k in range(K):
print(r)
r = g(P, m, r, n, goal)0.088
0.08595413598015118
0.08181584708758152
0.07393995779925847
0.060620588978863604
0.04232408431680751
0.023903282768700372
0.011019322624773925
0.004435781760615524
0.00166953516301453
0.0006111365088416604
0.00022135352318931154
7.986318129741709e-05
2.8773622932430686e-05
1.036147291845113e-05
3.73051516348033e-06
1.3430353515948567e-06
4.834991932942678e-07
1.74060547439403e-07
6.266190564829798e-08
x = numpy.linspace(0.2, 1.0, 100)
fig = plt.figure(figsize=(16, 6))
axes = fig.add_subplot(1, 2, 1)
axes.plot(x, numpy.exp(-x), "r", label="g(x)=exp(-x)$")
axes.plot(x, x, label="$x$")
axes.set_xlabel("$x$", fontsize=16)
axes.legend()
plt.grid()
f = lambda x: x - numpy.exp(-x)
axes = fig.add_subplot(1, 2, 2)
axes.plot(x, f(x), label="$f(x) = x - g(x)$")
axes.plot(x, numpy.zeros(x.shape), "r--", label="$0$")
axes.set_xlabel("$x$", fontsize=16)
axes.set_ylabel("residual", fontsize=16)
axes.ticklabel_format(axis="y", style="sci", scilimits=(-1, 1))
axes.legend(fontsize=14)
axes.grid()
plt.show()
plt.show()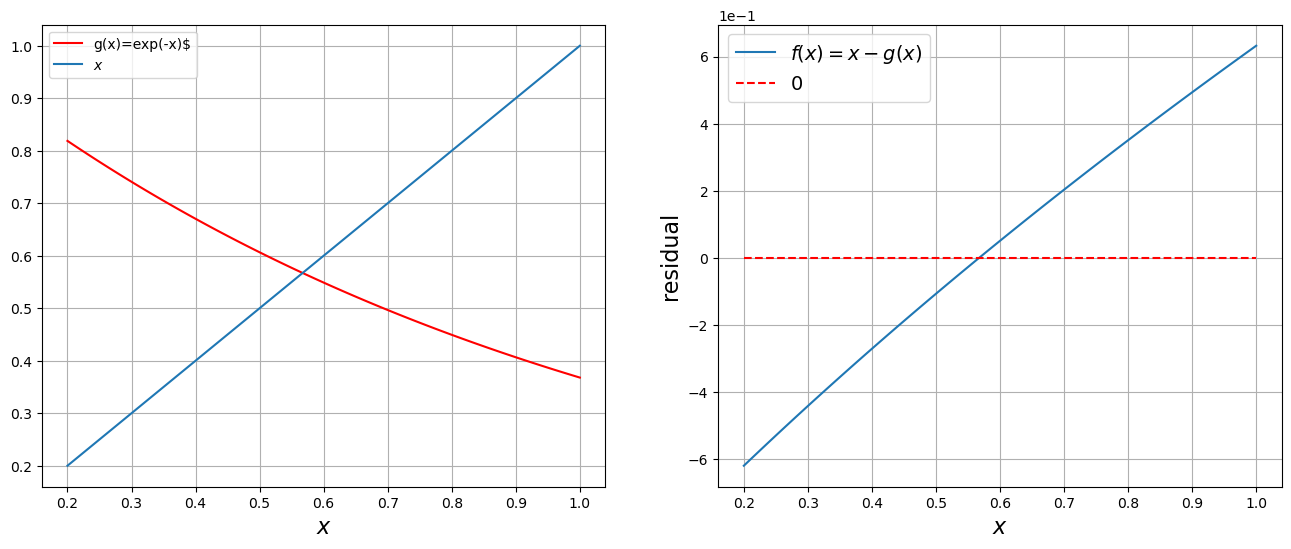
or again in code
x = x0
for i in range(N):
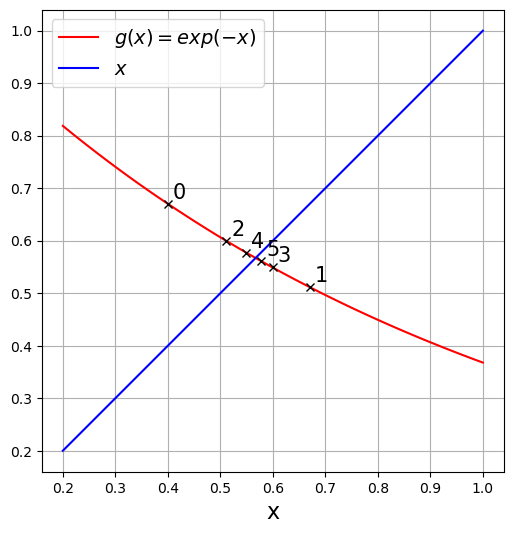
x = g(x)x = numpy.linspace(0.2, 1.0, 100)
fig = plt.figure(figsize=(8, 6))
axes = fig.add_subplot(1, 1, 1)
axes.plot(x, numpy.exp(-x), "r", label="$g(x)=exp(-x)$")
axes.plot(x, x, "b", label="$x$")
axes.set_xlabel("x", fontsize=16)
axes.set_aspect("equal")
axes.legend(fontsize=14)
x = 0.4
print("\tx\t exp(-x)\t residual")
for steps in range(6):
residual = numpy.abs(numpy.exp(-x) - x)
print("{:12.7f}\t{:12.7f}\t{:12.7f}".format(x, numpy.exp(-x), residual))
axes.plot(x, numpy.exp(-x), "kx")
axes.text(x + 0.01, numpy.exp(-x) + 0.01, steps, fontsize="15")
x = numpy.exp(-x)
plt.grid()
plt.show() x exp(-x) residual
0.4000000 0.6703200 0.2703200
0.6703200 0.5115448 0.1587752
0.5115448 0.5995686 0.0880238
0.5995686 0.5490484 0.0505202
0.5490484 0.5774991 0.0284507
0.5774991 0.5613004 0.0161987
x = numpy.linspace(0.1, 1.0, 100)
fig = plt.figure(figsize=(8, 6))
axes = fig.add_subplot(1, 1, 1)
axes.plot(x, -numpy.log(x), "r", label="$g(x)=-\log(x)$")
axes.plot(x, x, "b", label="$x$")
axes.set_xlabel("x", fontsize=16)
axes.set_ylabel("f(x)", fontsize=16)
axes.set_ylim([0, 1.5])
axes.set_aspect("equal")
axes.legend(loc="best", fontsize=14)
x = 0.55
print("\tx\t -log(x)\t residual")
for steps in range(5):
residual = numpy.abs(numpy.log(x) + x)
print("{:12.7f}\t{:12.7f}\t{:12.7f}".format(x, -numpy.log(x), residual))
axes.plot(x, -numpy.log(x), "kx")
axes.text(x + 0.01, -numpy.log(x) + 0.01, steps, fontsize="15")
x = -numpy.log(x)
plt.grid()
plt.show() x -log(x) residual
0.5500000 0.5978370 0.0478370
0.5978370 0.5144371 0.0833999
0.5144371 0.6646819 0.1502448
0.6646819 0.4084467 0.2562352
0.4084467 0.8953939 0.4869472
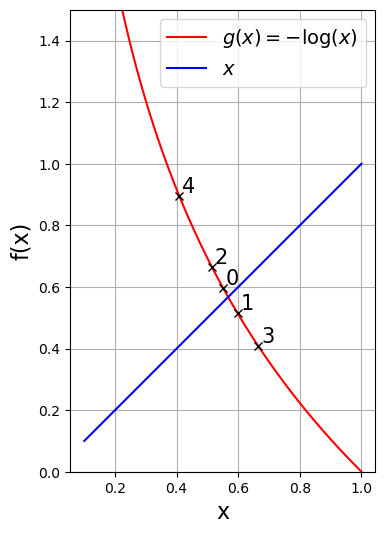
These are equivalent problems!¶
Something is awry...
Analysis of Fixed Point Iteration¶
Existence and uniqueness of fixed point problems
Existence:
Assume , if the range of the mapping satisfies then has a fixed point in .
x = numpy.linspace(0.0, 1.0, 100)
# Plot function and intercept
fig = plt.figure(figsize=(8, 6))
axes = fig.add_subplot(1, 1, 1)
axes.plot(x, numpy.exp(-x), "r", label="$g(x)$")
axes.plot(x, x, "b", label="$x$")
axes.set_xlabel("x", fontsize=16)
axes.legend(loc="best", fontsize=14)
axes.set_title("$g(x) = e^{-x}$", fontsize=24)
# Plot domain and range
axes.plot(numpy.ones(x.shape) * 0.4, x, "--k")
axes.plot(numpy.ones(x.shape) * 0.8, x, "--k")
axes.plot(x, numpy.ones(x.shape) * numpy.exp(-0.4), "--k")
axes.plot(x, numpy.ones(x.shape) * numpy.exp(-0.8), "--k")
axes.plot(x, numpy.ones(x.shape) * 0.4, "--", color="gray", linewidth=0.5)
axes.plot(x, numpy.ones(x.shape) * 0.8, "--", color="gray", linewidth=0.5)
axes.set_xlim((0.0, 1.0))
axes.set_ylim((0.0, 1.0))
axes.set_aspect("equal")
plt.show()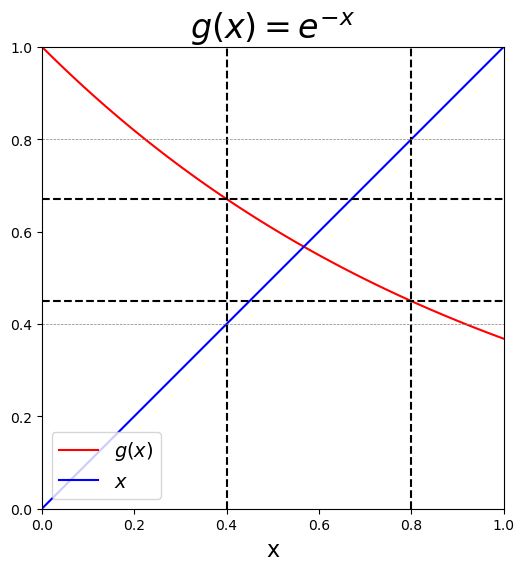
x = numpy.linspace(0.1, 1.0, 100)
fig = plt.figure(figsize=(8, 6))
axes = fig.add_subplot(1, 1, 1)
axes.plot(x, -numpy.log(x), "r", label="$g(x)$")
axes.plot(x, x, "b", label="$x$")
axes.set_xlabel("x", fontsize=16)
axes.set_xlim([0.1, 1.0])
axes.set_ylim([0.1, 1.0])
axes.legend(loc="best", fontsize=14)
axes.set_title("$g(x) = -\ln(x)$", fontsize=24)
axes.set_aspect("equal")
# Plot domain and range
axes.plot(numpy.ones(x.shape) * 0.4, x, "--k")
axes.plot(numpy.ones(x.shape) * 0.8, x, "--k")
axes.plot(x, numpy.ones(x.shape) * -numpy.log(0.4), "--k")
axes.plot(x, numpy.ones(x.shape) * -numpy.log(0.8), "--k")
axes.plot(x, numpy.ones(x.shape) * 0.4, "--", color="gray", linewidth=0.5)
axes.plot(x, numpy.ones(x.shape) * 0.8, "--", color="gray", linewidth=0.5)
plt.show()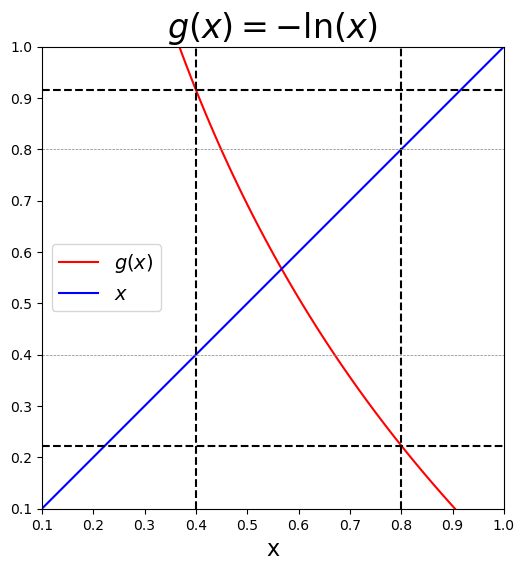
x = numpy.linspace(0.4, 0.8, 100)
fig = plt.figure(figsize=(8, 6))
axes = fig.add_subplot(1, 1, 1)
axes.plot(x, numpy.abs(-numpy.exp(-x)), "r")
axes.plot(x, numpy.ones(x.shape), "k--")
axes.set_xlabel("$x$", fontsize=18)
axes.set_ylabel("$|g\,'(x)|$", fontsize=18)
axes.set_ylim((0.0, 1.1))
axes.set_title("$g(x) = e^{-x}$", fontsize=20)
axes.grid()
plt.show()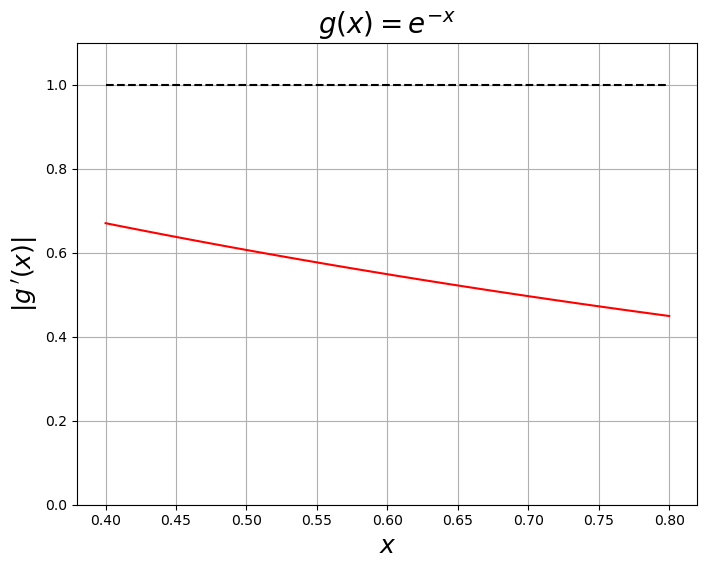
Asymptotic convergence: Behavior of fixed point iterations
Assume that a fixed point exists, such that
Then define
substituting
Evaluate
Taylor expand about and substitute
Note that because these terms cancel leaving
So if we can conclude that
which shows convergence. Also note that is related to .
Convergence of iterative schemes¶
Given any iterative scheme where
If and:
then the scheme is linearly convergent
then the scheme is quadratically convergent
the scheme can also be called superlinearly convergent
If then the scheme is divergent
Example 3: The retirement problem
r, P, m, A, n = sympy.symbols("r P m A n")
g_sym = P * m / A * ((1 + r / m) ** (m * n) - 1)
g_symg_prime = g_sym.diff(r)
g_primer_star = 0.08985602484084668
print("g'(r*) = ", g_prime.subs({P: 1500.0, m: 12, n: 20, A: 1e6, r: r_star}))
print(
"g(r*) - r* = {}".format(
g_sym.subs({P: 1500.0, m: 12, n: 20, A: 1e6, r: r_star}) - r_star
)
)g'(r*) = 2.14108802539073
g(r*) - r* = 7.00606239689705E-12
Example 3: The retirement problem
f = sympy.lambdify(r, g_prime.subs({P: 1500.0, m: 12, n: 20, A: 1e6}))
g = sympy.lambdify(r, g_sym.subs({P: 1500.0, m: 12, n: 20, A: 1e6}))
r = numpy.linspace(-0.01, 0.1, 100)
fig = plt.figure(figsize=(7, 5))
fig.set_figwidth(2.0 * fig.get_figwidth())
axes = fig.add_subplot(1, 2, 1)
axes.plot(r, g(r), label="$g(r)$")
axes.plot(r, r, "r--", label="$r$")
axes.set_xlabel("r (interest rate)", fontsize=14)
axes.set_ylabel("$g(r)$", fontsize=14)
axes.set_title("Minimum rate for a 20 year retirement?", fontsize=14)
axes.set_ylim([0, 0.12])
axes.ticklabel_format(axis="y", style="sci", scilimits=(-1, 1))
axes.set_xlim((0.00, 0.1))
axes.set_ylim(g(0.00), g(0.1))
axes.legend()
axes.grid()
axes = fig.add_subplot(1, 2, 2)
axes.plot(r, f(r))
axes.plot(r, numpy.ones(r.shape), "k--")
axes.plot(r_star, f(r_star), "ro")
axes.plot(0.0, f(0.0), "ro")
axes.set_xlim((-0.01, 0.1))
axes.set_xlabel("$r$", fontsize=14)
axes.set_ylabel("$g'(r)$", fontsize=14)
axes.grid()
plt.show()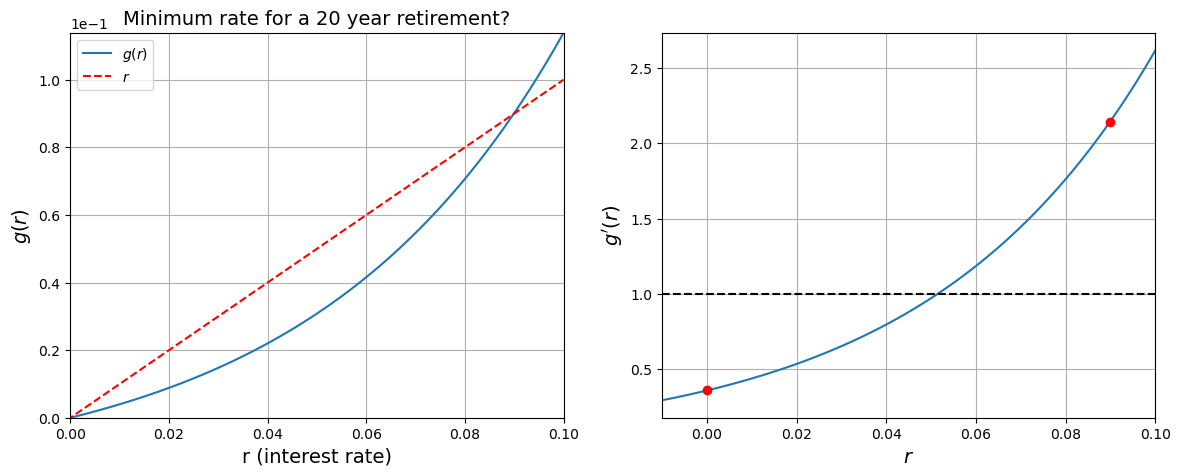
Better ways for root-finding/optimization¶
If is a fixed point of then is also a root of s.t. .
For instance:
or
Classical Methods¶
Bisection (linear convergence)
Newton’s Method (quadratic convergence)
Secant Method (super-linear)
Combined Methods¶
RootSafe (Newton + Bisection)
Brent’s Method (Secant + Bisection)
Bracketing and Bisection¶
A bracket is an interval that contains at least one zero or minima/maxima of interest.
In the case of a zero the bracket should satisfy
In the case of minima or maxima we need
Example: The retirement problem again. For fixed
P = 1500.0
m = 12
n = 20.0
A = 1e6
r = numpy.linspace(0.05, 0.1, 100)
f = lambda r, A, m, P, n: A - m * P / r * ((1.0 + r / m) ** (m * n) - 1.0)
fig = plt.figure(figsize=(8, 6))
axes = fig.add_subplot(1, 1, 1)
axes.plot(r, f(r, A, m, P, n), "b")
axes.plot(r, numpy.zeros(r.shape), "r--")
axes.set_xlabel("r", fontsize=16)
axes.set_ylabel("f(r)", fontsize=16)
axes.ticklabel_format(axis="y", style="sci", scilimits=(-1, 1))
axes.grid()
a = 0.075
b = 0.095
axes.plot(a, f(a, A, m, P, n), "ko")
axes.plot([a, a], [0.0, f(a, A, m, P, n)], "k--")
axes.plot(b, f(b, A, m, P, n), "ko")
axes.plot([b, b], [f(b, A, m, P, n), 0.0], "k--")
plt.show()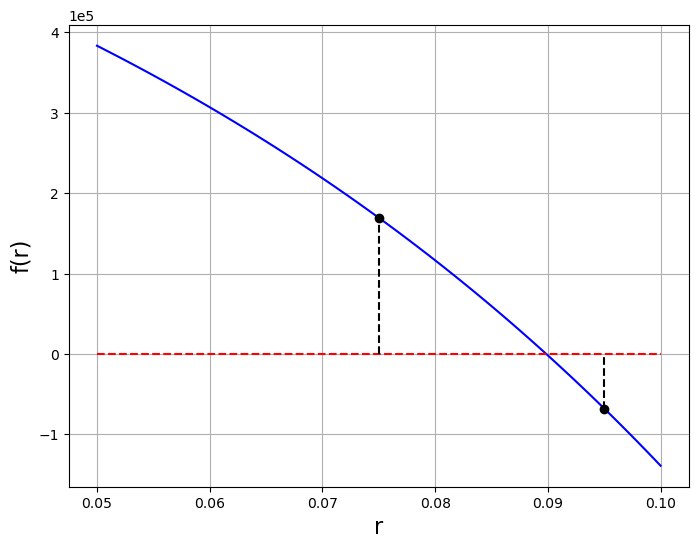
Basic bracketing algorithms shrink the bracket while ensuring that the root/extrema remains within the bracket.
What ways could we “shrink” the bracket so that the end points converge to the root/extrema?
Bisection Algorithm¶
Given a bracket and a function -
Initialize the bracket
Iterate
Cut the bracket in half and check which partition the zero is in (i.e. which partition is still a bracket)
Restart the algorithm using the new bracket
End when (or the width of the bracket is less than some tolerance)
basic code¶
def bisection(f,a,b,tol):
c = (a + b)/2.
f_a = f(a)
f_b = f(b)
f_c = f(c)
for step in range(1, MAX_STEPS + 1):
if numpy.abs(f_c) < tol:
break
if numpy.sign(f_a) != numpy.sign(f_c):
b = c
f_b = f_c
else:
a = c
f_a = f_c
c = (a + b)/ 2.0
f_c = f(c)
return cSome real code¶
# real code with standard bells and whistles
def bisection(f, a, b, tol=1.0e-6):
"""uses bisection to isolate a root x of a function of a single variable f such that f(x) = 0.
the root must exist within an initial bracket a < x < b
returns when f(x) at the midpoint of the bracket < tol
Parameters:
-----------
f: function of a single variable f(x) of type float
a: float
left bracket a < x
b: float
right bracket x < b
Note: the signs of f(a) and f(b) must be different to insure a bracket
tol: float
tolerance. Returns when |f((a+b)/2)| < tol
Returns:
--------
x: float
midpoint of final bracket
x_array: numpy array
history of bracket centers (for plotting later)
Raises:
-------
ValueError:
if initial bracket is invalid
Warning:
if number of iterations exceed MAX_STEPS
"""
MAX_STEPS = 1000
eps = numpy.finfo(float).eps
# initialize
c = (a + b) / 2.0
c_array = [c]
f_a = f(a)
f_b = f(b)
f_c = f(c)
# check bracket
if numpy.sign(f_a) == numpy.sign(f_b):
raise ValueError("no bracket: f(a) and f(b) must have different signs")
# Loop until we reach the TOLERANCE or we take MAX_STEPS
for step in range(1, MAX_STEPS + 1):
# Check tolerance - Could also check the size of delta_x
# We check this first as we have already initialized the values
# in c and f_c
if numpy.abs(f_c) < tol or numpy.abs(b - a) < eps * c:
break
if numpy.sign(f_a) != numpy.sign(f_c):
b = c
f_b = f_c
else:
a = c
f_a = f_c
c = (a + b) / 2.0
f_c = f(c)
c_array.append(c)
if step == MAX_STEPS:
warnings.warn("Maximum number of steps exceeded")
return c, numpy.array(c_array)# set up function as an inline lambda function
P = 1500.0
m = 12
n = 20.0
A = 1e6
f = lambda r: A - m * P / r * ((1.0 + r / m) ** (m * n) - 1.0)
# Initialize bracket
a = 0.07
b = 0.10# find root
r_star, r_array = bisection(f, a, b, tol=1e-8)
print("root at r = {}, f(r*) = {}, {} steps".format(r_star, f(r_star), len(r_array)))root at r = 0.08985602483470759, f(r*) = -9.080395102500916e-09, 40 steps
r = numpy.linspace(0.05, 0.11, 100)
# Setup figure to plot convergence
fig = plt.figure(figsize=(8, 6))
axes = fig.add_subplot(1, 1, 1)
axes.plot(r, f(r), "b")
axes.plot(r, numpy.zeros(r.shape), "r--")
axes.set_xlabel("r", fontsize=16)
axes.set_ylabel("f(r)", fontsize=16)
# axes.set_xlim([0.085, 0.091])
axes.ticklabel_format(axis="y", style="sci", scilimits=(-1, 1))
axes.plot(a, f(a), "ko")
axes.plot([a, a], [0.0, f(a)], "k--")
axes.text(a, f(a), str(0), fontsize="15")
axes.plot(b, f(b), "ko")
axes.plot([b, b], [f(b), 0.0], "k--")
axes.text(b, f(b), str(1), fontsize="15")
axes.grid()
# plot out the first N steps
N = 5
for k, r in enumerate(r_array[:N]):
# Plot iteration
axes.plot(r, f(r), "kx")
axes.text(r, f(r), str(k + 2), fontsize="15")
axes.plot(r_star, f(r_star), "go", markersize=10)
axes.set_title("Bisection method: first {} steps".format(N), fontsize=20)
plt.show()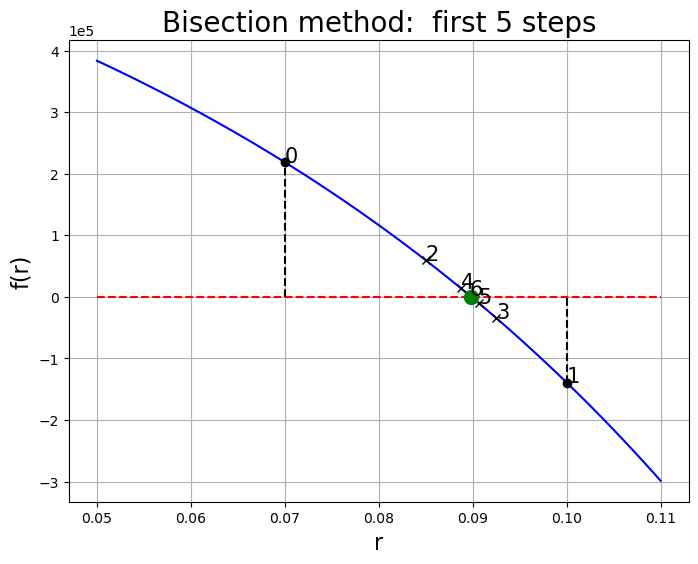
What is the smallest tolerance that can be achieved with this routine? Why?
# find root
r_star, r_array = bisection(f, a, b, tol=1e-8)
print("root at r = {}, f(r*) = {}, {} steps".format(r_star, f(r_star), len(r_array)))root at r = 0.08985602483470759, f(r*) = -9.080395102500916e-09, 40 steps
# this might be useful
print(numpy.diff(r_array))[ 7.50000000e-03 -3.75000000e-03 1.87500000e-03 -9.37500000e-04
4.68750000e-04 -2.34375000e-04 -1.17187500e-04 5.85937500e-05
-2.92968750e-05 1.46484375e-05 7.32421875e-06 3.66210937e-06
-1.83105469e-06 -9.15527344e-07 -4.57763672e-07 -2.28881836e-07
-1.14440918e-07 -5.72204590e-08 2.86102295e-08 -1.43051147e-08
-7.15255737e-09 3.57627869e-09 -1.78813934e-09 8.94069666e-10
4.47034840e-10 2.23517413e-10 1.11758713e-10 -5.58793567e-11
2.79396783e-11 -1.39698392e-11 6.98492653e-12 3.49245632e-12
-1.74622816e-12 -8.73121020e-13 -4.36553571e-13 2.18283724e-13
1.09134923e-13 5.45674617e-14 2.72837308e-14]
Convergence of Bisection¶
Generally have
where we need and .
Letting be the width of the th bracket we can then estimate the error with
and therefore
Due to the relationship then between and we then know
so therefore the method is linearly convergent.
Newton’s Method (Newton-Raphson)¶
Given a bracket, bisection is guaranteed to converge linearly to a root
However bisection uses almost no information about beyond its sign at a point
Can we do “better”? Newton’s method, when well behaved can achieve quadratic convergence.
Basic Ideas: There are multiple interpretations we can use to derive Newton’s method
Use Taylor’s theorem to estimate a correction to minimize the residual
A geometric interpretation that approximates locally as a straight line to predict where might be.
As a special case of a fixed-point iteration
Perhaps the simplest derivation uses Taylor series. Consider an initial guess at point . For arbitrary , it’s unlikely . However we can hope there is a correction such that at
and
expanding in a Taylor series around point
substituting into and dropping the higher order terms gives
substituting into and dropping the higher order terms gives
or solving for the correction
which leads to the update for the next iteration
or
rinse and repeat, as it’s still unlikely that (but we hope the error will be reduced)
Geometric interpretation¶
By truncating the taylor series at first order, we are locally approximating as a straight line tangent to the point . If the function was linear at that point, we could find its intercept such that
P = 1500.0
m = 12
n = 20.0
A = 1e6
r = numpy.linspace(0.05, 0.11, 100)
f = lambda r, A=A, m=m, P=P, n=n: A - m * P / r * ((1.0 + r / m) ** (m * n) - 1.0)
f_prime = (
lambda r, A=A, m=m, P=P, n=n: -P
* m
* n
* (1.0 + r / m) ** (m * n)
/ (r * (1.0 + r / m))
+ P * m * ((1.0 + r / m) ** (m * n) - 1.0) / r**2
)
# Initial guess
x_k = 0.06
# Setup figure to plot convergence
fig = plt.figure(figsize=(8, 6))
axes = fig.add_subplot(1, 1, 1)
axes.plot(r, f(r), "b")
axes.plot(r, numpy.zeros(r.shape), "r--")
# Plot x_k point
axes.plot([x_k, x_k], [0.0, f(x_k)], "k--")
axes.plot(x_k, f(x_k), "ko")
axes.text(x_k, -5e4, "$x_k$", fontsize=16)
axes.plot(x_k, 0.0, "xk")
axes.text(x_k, f(x_k) + 2e4, "$f(x_k)$", fontsize=16)
axes.plot(r, f_prime(x_k) * (r - x_k) + f(x_k), "k")
# Plot x_{k+1} point
x_k = x_k - f(x_k) / f_prime(x_k)
axes.plot([x_k, x_k], [0.0, f(x_k)], "k--")
axes.plot(x_k, f(x_k), "ko")
axes.text(x_k, 1e4, "$x_{k+1}$", fontsize=16)
axes.plot(x_k, 0.0, "xk")
axes.text(0.0873, f(x_k) - 2e4, "$f(x_{k+1})$", fontsize=16)
axes.set_xlabel("r", fontsize=16)
axes.set_ylabel("f(r)", fontsize=16)
axes.set_title("Newton-Raphson Steps", fontsize=18)
axes.ticklabel_format(axis="y", style="sci", scilimits=(-1, 1))
axes.grid()
plt.show()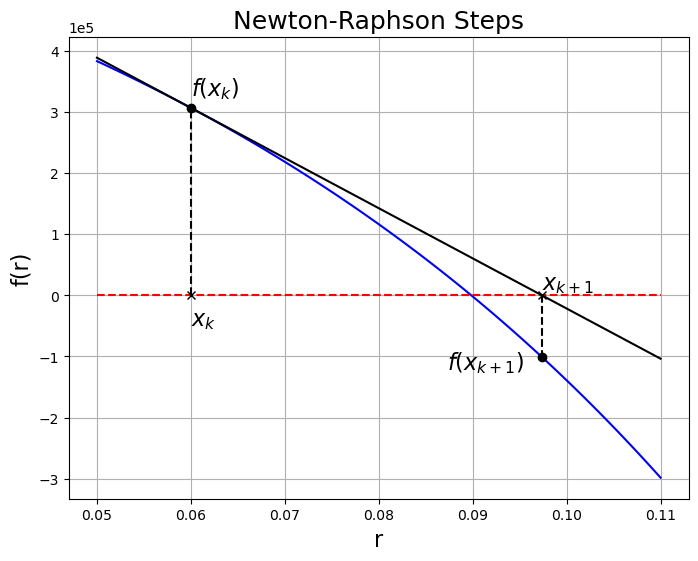
If we simply approximate the derivative with its finite difference approximation
we can rearrange to find as
which is the classic Newton-Raphson iteration
Some code¶
def newton(f, f_prime, x0, tol=1.0e-6):
"""uses newton's method to find a root x of a function of a single variable f
Parameters:
-----------
f: function f(x)
returns type: float
f_prime: function f'(x)
returns type: float
x0: float
initial guess
tolerance: float
Returns when |f(x)| < tol
Returns:
--------
x: float
final iterate
x_array: numpy array
history of iteration points
Raises:
-------
Warning:
if number of iterations exceed MAX_STEPS
"""
MAX_STEPS = 200
x = x0
x_array = [x0]
for k in range(1, MAX_STEPS + 1):
x = x - f(x) / f_prime(x)
x_array.append(x)
if numpy.abs(f(x)) < tol:
break
if k == MAX_STEPS:
warnings.warn("Maximum number of steps exceeded")
return x, numpy.array(x_array)Set the problem up¶
P = 1500.0
m = 12
n = 20.0
A = 1e6
f = lambda r, A=A, m=m, P=P, n=n: A - m * P / r * ((1.0 + r / m) ** (m * n) - 1.0)
f_prime = (
lambda r, A=A, m=m, P=P, n=n: -P
* m
* n
* (1.0 + r / m) ** (m * n)
/ (r * (1.0 + r / m))
+ P * m * ((1.0 + r / m) ** (m * n) - 1.0) / r**2
)and solve¶
x0 = 0.06
x, x_array = newton(f, f_prime, x0, tol=1.0e-8)
print(
"x = {}, f(x) = {},f'(x)={:g} Nsteps = {}".format(x, f(x), f_prime(x), len(x_array))
)x = 0.08985602483470316, f(x) = 5.122274160385132e-09,f'(x)=-1.26991e+07 Nsteps = 6
r = numpy.linspace(0.05, 0.10, 100)
# Setup figure to plot convergence
fig = plt.figure(figsize=(16, 6))
axes = fig.add_subplot(1, 2, 1)
axes.plot(r, f(r), "b")
axes.plot(r, numpy.zeros(r.shape), "r--")
for n, x in enumerate(x_array):
axes.plot(x, f(x), "kx")
axes.text(x, f(x), str(n), fontsize="15")
axes.set_xlabel("r", fontsize=16)
axes.set_ylabel("f(r)", fontsize=16)
axes.set_title("Newton-Raphson Steps", fontsize=18)
axes.grid()
axes.ticklabel_format(axis="y", style="sci", scilimits=(-1, 1))
axes = fig.add_subplot(1, 2, 2)
axes.semilogy(numpy.arange(len(x_array)), numpy.abs(f(x_array)), "bo-")
axes.grid()
axes.set_xlabel("Iterations", fontsize=16)
axes.set_ylabel("Residual $|f(r)|$", fontsize=16)
axes.set_title("Convergence", fontsize=18)
plt.show()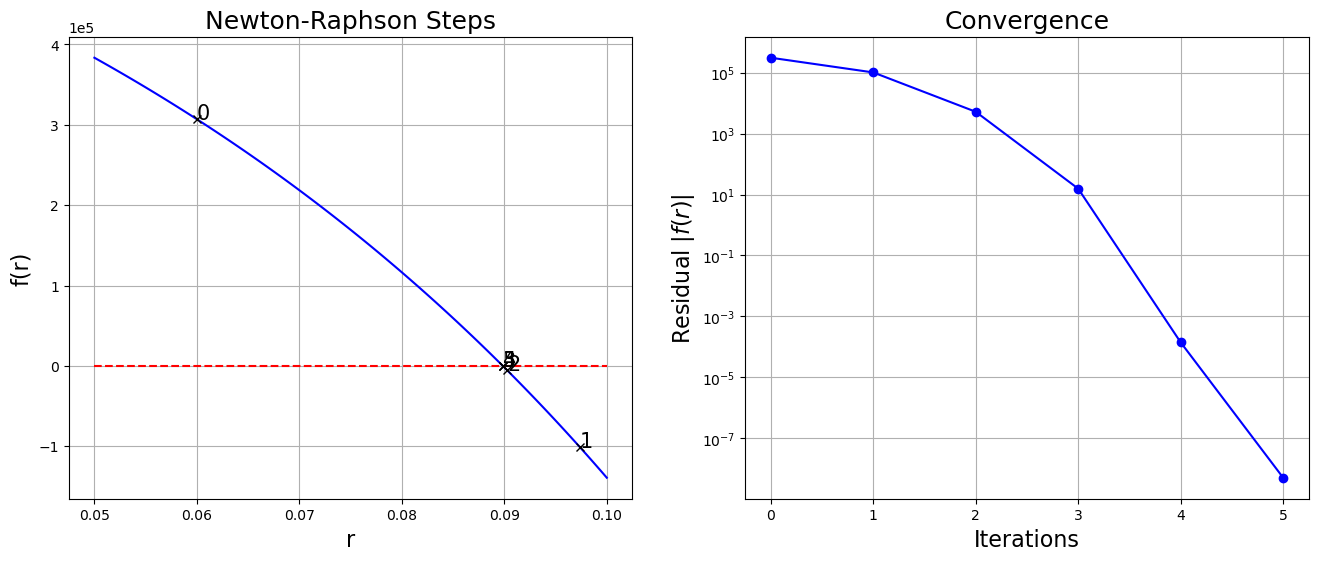
What is the smallest tolerance that can be achieved with this routine? Why?
setup in sympy¶
x = sympy.symbols("x")
f = x - sympy.exp(-x)
f_prime = f.diff(x)
f, f_primef = sympy.lambdify(x, f)
f_prime = sympy.lambdify(x, f_prime)
print(f(0.0), f_prime(0.0))-1.0 2.0
and solve¶
x0 = 0.0
x, x_array = newton(f, f_prime, x0, tol=1.0e-8)
print("x = {}, f(x) = {}, Nsteps = {}".format(x, f(x), len(x_array)))x = 0.5671432904097811, f(x) = -4.440892098500626e-15, Nsteps = 5
xa = numpy.linspace(-1, 1, 100)
fig = plt.figure(figsize=(16, 6))
axes = fig.add_subplot(1, 2, 1)
axes.plot(xa, f(xa), "b")
axes.plot(xa, numpy.zeros(xa.shape), "r--")
axes.plot(x, f(x), "go", markersize=10)
axes.plot(x0, f(x0), "kx", markersize=10)
axes.grid()
axes.set_xlabel("x", fontsize=16)
axes.set_ylabel("f(x)", fontsize=16)
axes.set_title("$f(x) = x - e^{-x}$", fontsize=18)
axes = fig.add_subplot(1, 2, 2)
axes.semilogy(numpy.arange(len(x_array)), numpy.abs(f(x_array)), "bo-")
axes.grid()
axes.set_xlabel("Iterations", fontsize=16)
axes.set_ylabel("Residual $|f(r)|$", fontsize=16)
axes.set_title("Convergence", fontsize=18)
plt.show()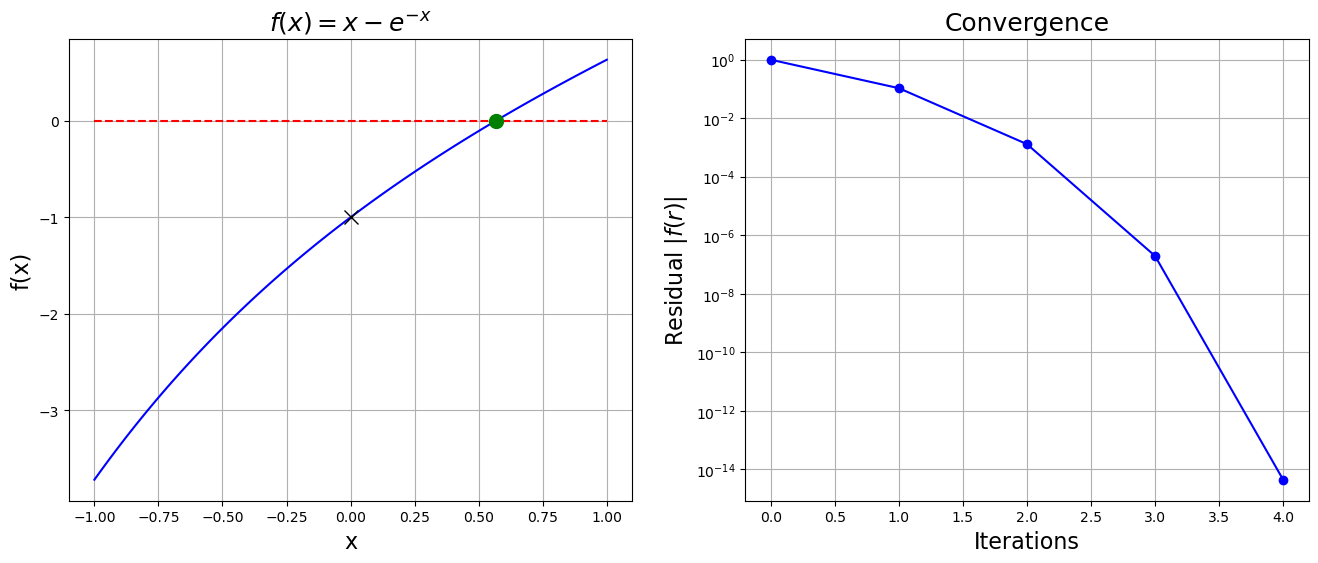
Asymptotic Convergence of Newton’s Method¶
Newton’s method can be also considered a fixed point iteration
with
Again if is the fixed point and the error at iteration :
Taylor Expansion around
Note that as before and cancel:
What about though?
Example: Convergence for a non-simple root¶
Consider our first problem
the case is, unfortunately, not as rosey. Why might this be?
Setup the problem¶
f = lambda x: x * x + x - numpy.sin(x)
f_prime = lambda x: 2 * x + 1.0 - numpy.cos(x)
x0 = 0.9
x, x_array = newton(f, f_prime, x0, tol=1.0e-16)
print("x = {}, f(x) = {}, Nsteps = {}".format(x, f(x), len(x_array)))x = 7.608160216892554e-09, f(x) = 5.788410245246217e-17, Nsteps = 28
xa = numpy.linspace(-2, 2, 100)
fig = plt.figure(figsize=(16, 6))
axes = fig.add_subplot(1, 2, 1)
axes.plot(xa, f(xa), "b")
axes.plot(xa, numpy.zeros(xa.shape), "r--")
axes.plot(x, f(x), "go", markersize=10)
axes.plot(x0, f(x0), "kx", markersize=10)
axes.grid()
axes.set_xlabel("x", fontsize=16)
axes.set_ylabel("f(x)", fontsize=16)
axes.set_title("$f(x) = x^2 +x - sin(x)$", fontsize=18)
axes = fig.add_subplot(1, 2, 2)
axes.semilogy(numpy.arange(len(x_array)), numpy.abs(f(x_array)), "bo-")
axes.grid()
axes.set_xlabel("Iterations", fontsize=16)
axes.set_ylabel("Residual $|f(r)|$", fontsize=16)
axes.set_title("Convergence", fontsize=18)
plt.show()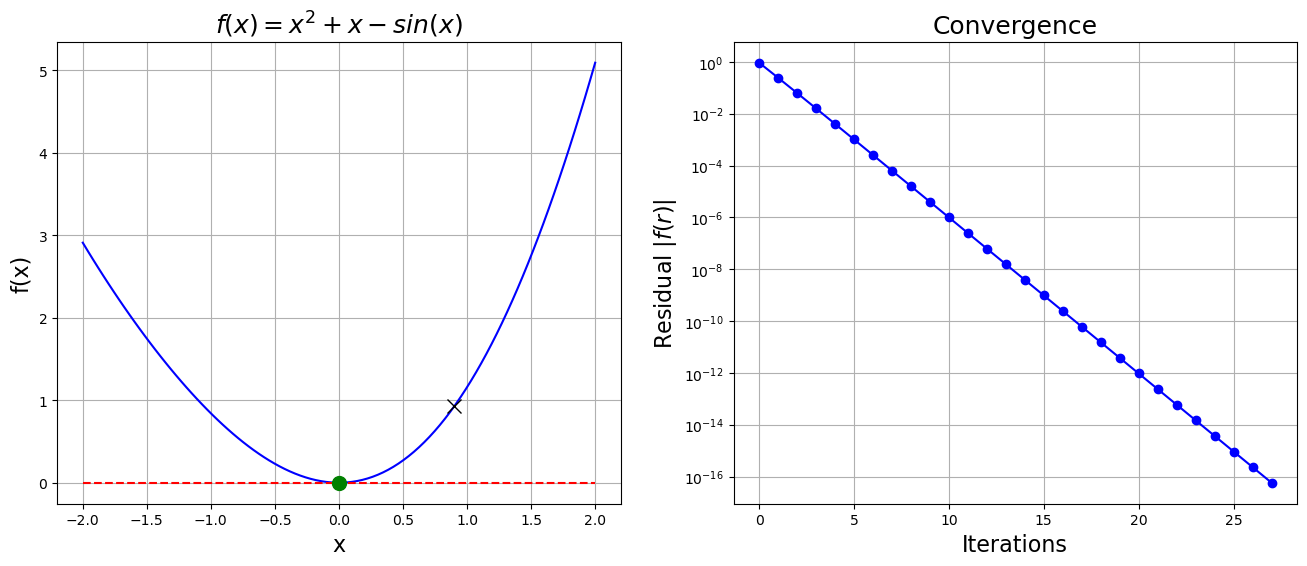
x = numpy.linspace(0, 2, 1000)
f = lambda x: numpy.sin(2.0 * numpy.pi * x)
f_prime = lambda x: 2.0 * numpy.pi * numpy.cos(2.0 * numpy.pi * x)
x_kp = lambda x: x - f(x) / f_prime(x)
fig = plt.figure(figsize=(16, 6))
axes = fig.add_subplot(1, 2, 1)
axes.plot(x, f(x), "b")
axes.plot(x, f_prime(x), "r")
axes.set_xlabel("x")
axes.set_ylabel("y")
axes.set_title("Comparison of $f(x)$ and $f'(x)$")
axes.set_ylim((-2, 2))
axes.set_xlim((0, 2))
axes.plot(x, numpy.zeros(x.shape), "k--")
x_k = 0.3
axes.plot([x_k, x_k], [0.0, f(x_k)], "ko")
axes.plot([x_k, x_k], [0.0, f(x_k)], "k--")
axes.plot(x, f_prime(x_k) * (x - x_k) + f(x_k), "k")
x_k = x_k - f(x_k) / f_prime(x_k)
axes.plot([x_k, x_k], [0.0, f(x_k)], "ko")
axes.plot([x_k, x_k], [0.0, f(x_k)], "k--")
axes = fig.add_subplot(1, 2, 2)
axes.plot(x, f(x), "b")
axes.plot(x, x_kp(x), "r")
axes.set_xlabel("x")
axes.set_ylabel("y")
axes.set_title("Comparison of $f(x)$ and $x_{k+1}(x)$", fontsize=18)
axes.set_ylim((-2, 2))
axes.set_xlim((0, 2))
axes.plot(x, numpy.zeros(x.shape), "k--")
plt.show()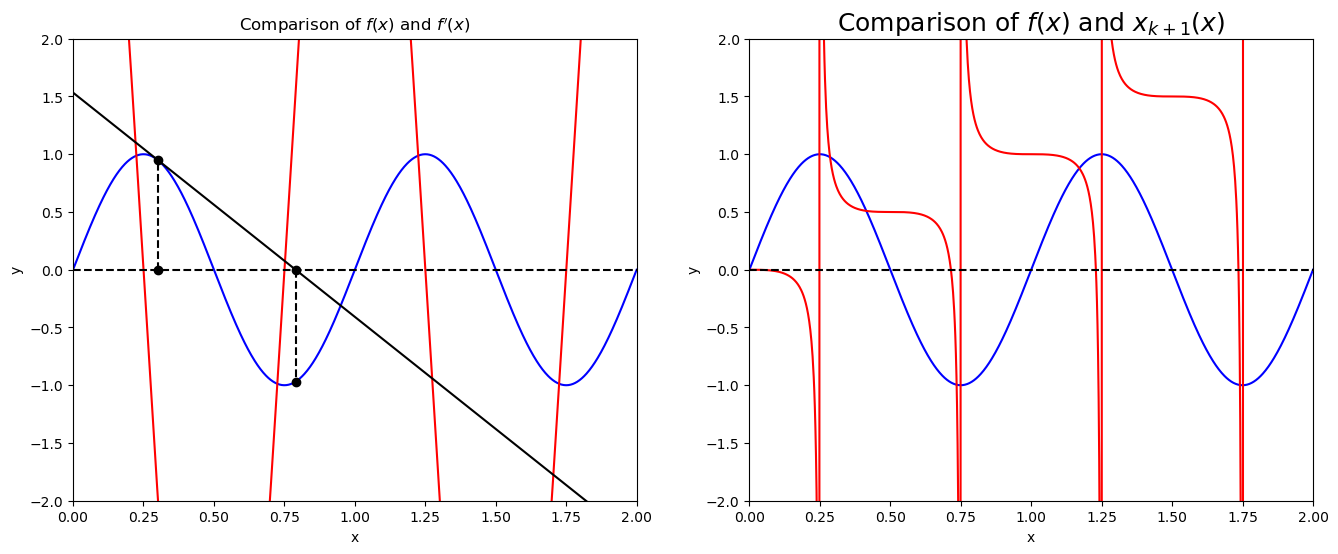
Basins of Attraction¶
Given a point can we determine if Newton-Raphson converges and to which root it converges to?
A basin of attraction for Newton’s methods is defined as the set such that Newton iterations converges to the same root. Unfortunately this is far from a trivial thing to determine and even for simple functions can lead to regions that are complicated or even fractal.
# calculate the basin of attraction for f(x) = sin(2\pi x)
x_root = numpy.zeros(x.shape)
N_steps = numpy.zeros(x.shape)
for i, xk in enumerate(x):
x_root[i], x_root_array = newton(f, f_prime, xk)
N_steps[i] = len(x_root_array)y = numpy.linspace(-2, 2)
X, Y = numpy.meshgrid(x, y)
X_root = numpy.outer(numpy.ones(y.shape), x_root)
plt.figure(figsize=(8, 6))
plt.pcolor(X, Y, X_root, vmin=-5, vmax=5, cmap="seismic")
cbar = plt.colorbar()
cbar.set_label("$x_{root}$", fontsize=18)
plt.plot(x, f(x), "k-")
plt.plot(x, numpy.zeros(x.shape), "k--", linewidth=0.5)
plt.xlabel("x", fontsize=16)
plt.title("Basins of Attraction: $f(x) = \sin{2\pi x}$", fontsize=18)
# plt.xlim(0.25-.1,0.25+.1)
plt.show()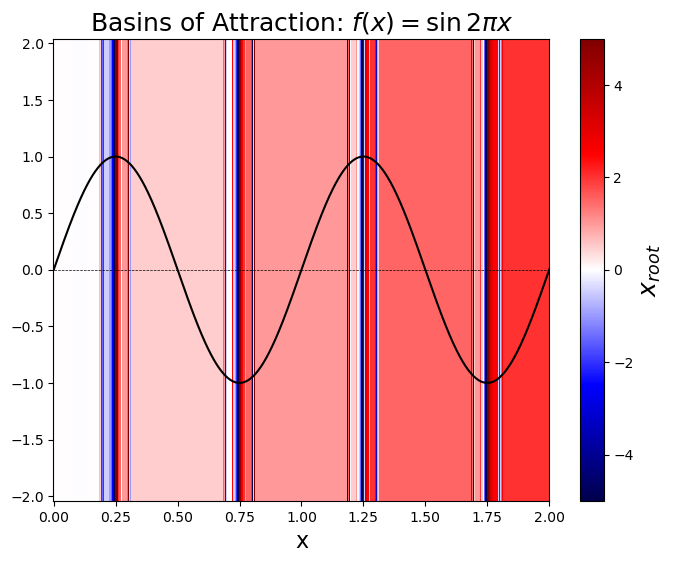
Fractal Basins of Attraction¶
If is complex (for complex), then the basins of attraction can be beautiful and fractal
Plotted below are two fairly simple equations which demonstrate the issue:
Kepler’s equation
f = lambda x: x**3 - 1
f_prime = lambda x: 3 * x**2
N = 1001
x = numpy.linspace(-2, 2, N)
X, Y = numpy.meshgrid(x, x)
R = X + 1j * Y
for i in range(30):
R = R - f(R) / f_prime(R)
# print(numpy.imag(R))
roots = numpy.roots([1.0, 0.0, 0.0, -1])
fig = plt.figure()
fig.set_figwidth(fig.get_figwidth() * 2)
fig.set_figheight(fig.get_figheight() * 2)
axes = fig.add_subplot(1, 1, 1, aspect="equal")
# axes.contourf(X, Y, numpy.sign(numpy.imag(R))*numpy.abs(R),vmin = -10, vmax = 10)
cf = axes.contourf(X, Y, numpy.real(R), vmin=-8, vmax=8)
axes.scatter(numpy.real(roots), numpy.imag(roots))
axes.set_xlabel("Real")
axes.set_ylabel("Imaginary")
axes.set_title("Basin of Attraction for $f(x) = x^3 - 1$")
axes.grid()
plt.show()/tmp/ipykernel_228028/4129415880.py:10: RuntimeWarning: divide by zero encountered in divide
R = R - f(R) / f_prime(R)
/tmp/ipykernel_228028/4129415880.py:10: RuntimeWarning: invalid value encountered in divide
R = R - f(R) / f_prime(R)
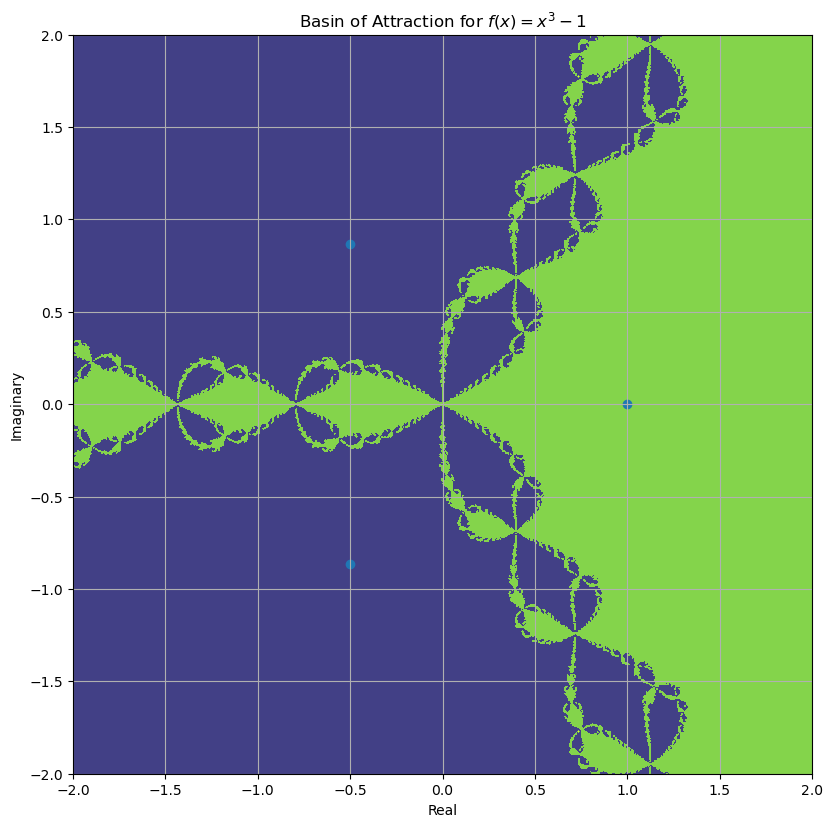
def f(theta, e=0.083, M=1):
return theta - e * numpy.sin(theta) - M
def f_prime(theta, e=0.083):
return 1 - e * numpy.cos(theta)
N = 1001
x = numpy.linspace(-30.5, -29.5, N)
y = numpy.linspace(-17.5, -16.5, N)
X, Y = numpy.meshgrid(x, y)
R = X + 1j * Y
for i in range(30):
R = R - f(R) / f_prime(R)
fig = plt.figure()
fig.set_figwidth(fig.get_figwidth() * 2)
fig.set_figheight(fig.get_figheight() * 2)
axes = fig.add_subplot(1, 1, 1, aspect="equal")
axes.contourf(X, Y, R, vmin=0, vmax=10)
axes.set_xlabel("Real")
axes.set_ylabel("Imaginary")
axes.set_title("Basin of Attraction for $f(x) = x - e \sin x - M$")
plt.show()/tmp/ipykernel_228028/619130823.py:2: RuntimeWarning: overflow encountered in sin
return theta - e * numpy.sin(theta) - M
/tmp/ipykernel_228028/619130823.py:2: RuntimeWarning: invalid value encountered in multiply
return theta - e * numpy.sin(theta) - M
/tmp/ipykernel_228028/619130823.py:4: RuntimeWarning: overflow encountered in cos
return 1 - e * numpy.cos(theta)
/tmp/ipykernel_228028/619130823.py:4: RuntimeWarning: invalid value encountered in multiply
return 1 - e * numpy.cos(theta)
/tmp/ipykernel_228028/619130823.py:13: RuntimeWarning: invalid value encountered in divide
R = R - f(R) / f_prime(R)
/usr/lib/python3.13/site-packages/matplotlib/contour.py:1364: ComplexWarning: Casting complex values to real discards the imaginary part
self.zmax = z.max().astype(float)
/usr/lib/python3.13/site-packages/matplotlib/contour.py:1365: ComplexWarning: Casting complex values to real discards the imaginary part
self.zmin = z.min().astype(float)
/usr/lib/python3.13/site-packages/numpy/ma/core.py:2896: ComplexWarning: Casting complex values to real discards the imaginary part
_data = np.array(data, dtype=dtype, copy=copy,
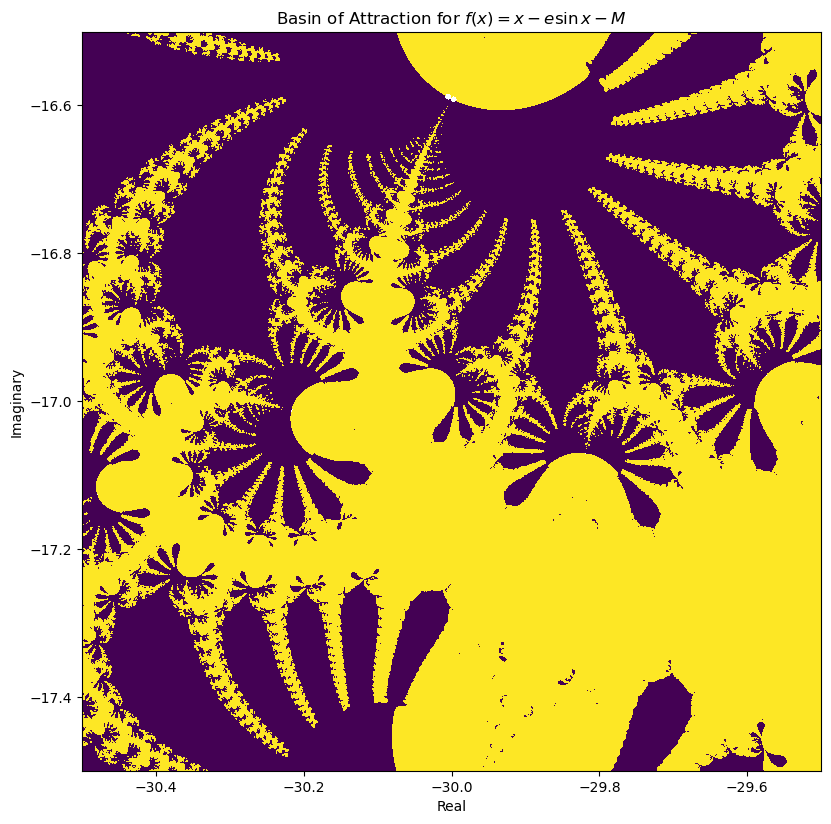
Other Issues¶
Need to supply both and , could be expensive
Example: FTV equation
Can use symbolic differentiation (sympy)
Secant Methods¶
Is there a method with the convergence of Newton’s method but without the extra derivatives? What way would you modify Newton’s method so that you would not need ?
Given and represent the derivative as the approximation
Combining this with the Newton approach leads to
This leads to superlinear convergence and not quite quadratic as the exponent on the convergence is .
Alternative interpretation, fit a line through two points and see where they intersect the x-axis.
P = 1500.0
m = 12
n = 20.0
A = 1e6
r = numpy.linspace(0.05, 0.11, 100)
f = lambda r, A=A, m=m, P=P, n=n: A - m * P / r * ((1.0 + r / m) ** (m * n) - 1.0)
# Initial guess
x_k = 0.07
x_km = 0.06
fig = plt.figure(figsize=(8, 6))
axes = fig.add_subplot(1, 1, 1)
axes.plot(r, f(r), "b")
axes.plot(r, numpy.zeros(r.shape), "r--")
axes.plot(x_k, 0.0, "ko")
axes.plot(x_k, f(x_k), "ko")
axes.plot([x_k, x_k], [0.0, f(x_k)], "k--")
axes.plot(x_km, 0.0, "ko")
axes.plot(x_km, f(x_km), "ko")
axes.plot([x_km, x_km], [0.0, f(x_km)], "k--")
axes.plot(r, (f(x_k) - f(x_km)) / (x_k - x_km) * (r - x_k) + f(x_k), "k")
x_kp = x_k - (f(x_k) * (x_k - x_km) / (f(x_k) - f(x_km)))
axes.plot(x_kp, 0.0, "ro")
axes.plot([x_kp, x_kp], [0.0, f(x_kp)], "r--")
axes.plot(x_kp, f(x_kp), "ro")
axes.set_xlabel("r", fontsize=16)
axes.set_ylabel("f(r)", fontsize=14)
axes.set_title("Secant Method", fontsize=18)
axes.ticklabel_format(axis="y", style="sci", scilimits=(-1, 1))
axes.grid()
plt.show()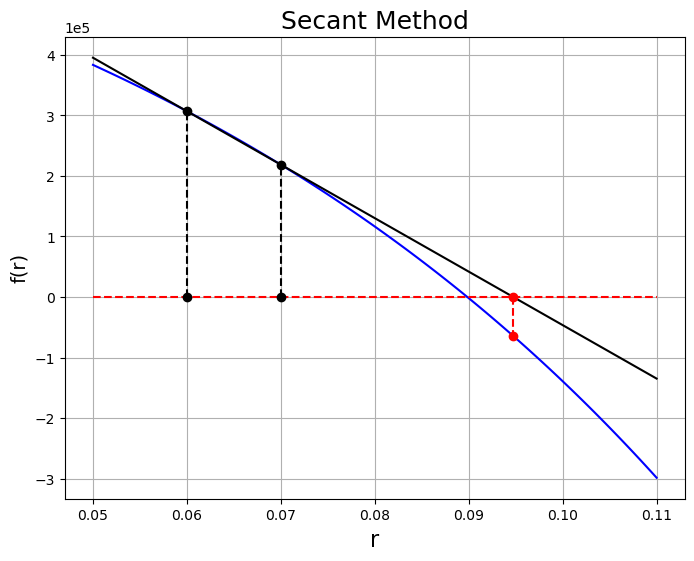
What would the algorithm look like for such a method?
Algorithm¶
Given , a TOLERANCE, and a MAX_STEPS
Initialize two points , , , and
Loop for k=2, to
MAX_STEPSis reached orTOLERANCEis achievedCalculate new update
Check for convergence and break if reached
Update parameters , , and
Some Code¶
def secant(f, x0, x1, tol=1.0e-6):
"""uses a linear secant method to find a root x of a function of a single variable f
Parameters:
-----------
f: function f(x)
returns type: float
x0: float
first point to initialize the algorithm
x1: float
second point to initialize the algorithm x1 != x0
tolerance: float
Returns when |f(x)| < tol
Returns:
--------
x: float
final iterate
x_array: numpy array
history of iteration points
Raises:
-------
ValueError:
if x1 is too close to x0
Warning:
if number of iterations exceed MAX_STEPS
"""
MAX_STEPS = 200
if numpy.isclose(x0, x1):
raise ValueError(
"Initial points are too close (preferably should be a bracket)"
)
x_array = [x0, x1]
for k in range(1, MAX_STEPS + 1):
x2 = x1 - f(x1) * (x1 - x0) / (f(x1) - f(x0))
x_array.append(x2)
if numpy.abs(f(x2)) < tol:
break
x0 = x1
x1 = x2
if k == MAX_STEPS:
warnings.warn("Maximum number of steps exceeded")
return x2, numpy.array(x_array)Set the problem up¶
P = 1500.0
m = 12
n = 20.0
A = 1e6
r = numpy.linspace(0.05, 0.11, 100)
f = lambda r, A=A, m=m, P=P, n=n: A - m * P / r * ((1.0 + r / m) ** (m * n) - 1.0)and solve¶
x0 = 0.06
x1 = 0.07
x, x_array = secant(f, x0, x1, tol=1.0e-7)
print("x = {}, f(x) = {}, Nsteps = {}".format(x, f(x), len(x_array)))x = 0.08985602483470356, f(x) = 9.66247171163559e-09, Nsteps = 8
r = numpy.linspace(0.05, 0.10, 100)
# Setup figure to plot convergence
fig = plt.figure(figsize=(16, 6))
axes = fig.add_subplot(1, 2, 1)
axes.plot(r, f(r), "b")
axes.plot(r, numpy.zeros(r.shape), "r--")
for n, x in enumerate(x_array):
axes.plot(x, f(x), "kx")
axes.text(x, f(x), str(n), fontsize="15")
axes.set_xlabel("r", fontsize=16)
axes.set_ylabel("f(r)", fontsize=16)
axes.set_title("Secant Method Steps", fontsize=18)
axes.grid()
axes.ticklabel_format(axis="y", style="sci", scilimits=(-1, 1))
axes = fig.add_subplot(1, 2, 2)
axes.semilogy(numpy.arange(len(x_array)), numpy.abs(f(x_array)), "bo-")
axes.grid()
axes.set_xlabel("Iterations", fontsize=16)
axes.set_ylabel("Residual $|f(r)|$", fontsize=16)
axes.set_title("Convergence", fontsize=18)
plt.show()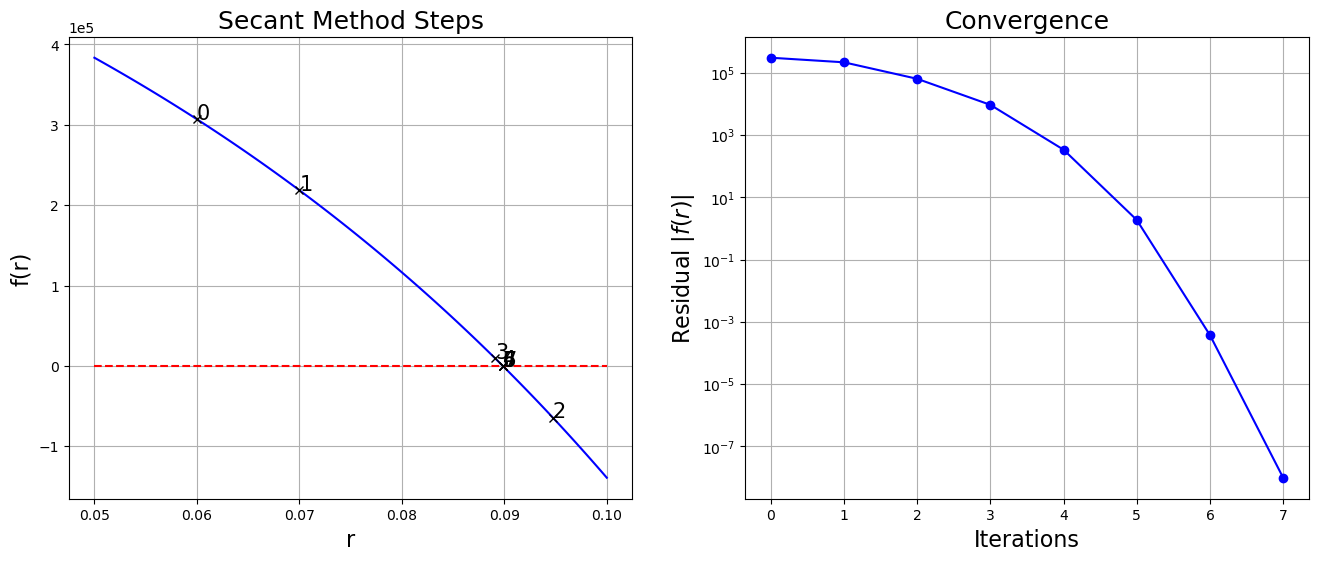
Comments¶
Secant method as shown is equivalent to linear interpolation
Can use higher order interpolation for higher order secant methods
Convergence is not quite quadratic
Not guaranteed to converge
Does not preserve brackets
Almost as good as Newton’s method if your initial guess is good.
Hybrid Methods¶
Combine attributes of methods with others to make one great algorithm to rule them all (not really)
Goals¶
Robustness: Given a bracket , maintain bracket
Efficiency: Use superlinear convergent methods when possible
Options¶
Methods requiring
NewtSafe (RootSafe, Numerical Recipes)
Newton’s Method within a bracket, Bisection otherwise
Methods not requiring
Brent’s Algorithm (zbrent, Numerical Recipes)
Combination of bisection, secant and inverse quadratic interpolation
scipy.optimizepackage new root_scalar
from scipy.optimize import root_scalar
# root_scalar?Set the problem up (again)¶
def f(r, A, m, P, n):
return A - m * P / r * ((1.0 + r / m) ** (m * n) - 1.0)
def f_prime(r, A, m, P, n):
return (
-P * m * n * (1.0 + r / m) ** (m * n) / (r * (1.0 + r / m))
+ P * m * ((1.0 + r / m) ** (m * n) - 1.0) / r**2
)
A = 1.0e6
m = 12
P = 1500.0
n = 20.0Try Brent’s method
a = 0.07
b = 0.1
sol = root_scalar(f, args=(A, m, P, n), bracket=(a, b), method="brentq")
print(sol) converged: True
flag: converged
function_calls: 8
iterations: 7
root: 0.08985602483470466
method: brentq
Try Newton’s method
sol = root_scalar(f, args=(A, m, P, n), x0=0.07, fprime=f_prime, method="newton")
print(sol) converged: True
flag: converged
function_calls: 10
iterations: 5
root: 0.08985602483470363
method: newton
f1 = lambda A: f(r, A, m, P, n)Optimization (finding extrema)¶
I want to find the extrema of a function on a given interval .
A few approaches:
Interpolation Algorithms: Repeated parabolic interpolation
Bracketing Algorithms: Golden-Section Search (linear)
Hybrid Algorithms
Use Rootfinding methods on
Interpolation Approach¶
Successive parabolic interpolation - similar to secant method
Basic idea: Fit polynomial to function using three points, find its minima, and guess new points based on that minima
What do we need to fit a polynomial of degree ?
How do we construct the polynomial ?
Once we have constructed how would we find the minimum?
Algorithm¶
Given and - Note that unlike a bracket these will be a sequence of better approximations to the minimum.
Initialize
Loop
Evaluate function at the three points
Find the quadratic polynomial that interpolates those points:
Calculate the minimum:
New set of points
Check tolerance
Demo¶
def f(t):
"""Simple function for minimization demos"""
return (
-3.0 * numpy.exp(-((t - 0.3) ** 2) / (0.1) ** 2)
+ numpy.exp(-((t - 0.6) ** 2) / (0.2) ** 2)
+ numpy.exp(-((t - 1.0) ** 2) / (0.2) ** 2)
+ numpy.sin(t)
- 2.0
)x0, x1 = 0.5, 0.2
x = numpy.array([x0, x1, (x0 + x1) / 2.0])
p = numpy.polyfit(x, f(x), 2)
parabola = lambda t: p[0] * t**2 + p[1] * t + p[2]
t_min = -p[1] / 2.0 / p[0]MAX_STEPS = 100
TOLERANCE = 1e-4
t = numpy.linspace(0.0, 2.0, 100)
fig = plt.figure(figsize=(8, 6))
axes = fig.add_subplot(1, 1, 1)
axes.plot(t, f(t), label="$f(t)$")
axes.set_xlabel("t (days)")
axes.set_ylabel("People (N)")
axes.set_title("Decrease in Population due to SPAM Poisoning")
axes.plot(x[0], f(x[0]), "ko")
axes.plot(x[1], f(x[1]), "ko")
axes.plot(x[2], f(x[2]), "ko")
axes.plot(t, parabola(t), "r--", label="parabola")
axes.plot(t_min, parabola(t_min), "ro")
axes.plot(t_min, f(t_min), "k+")
axes.legend(loc="best")
axes.set_ylim((-5, 0.0))
axes.grid()
plt.show()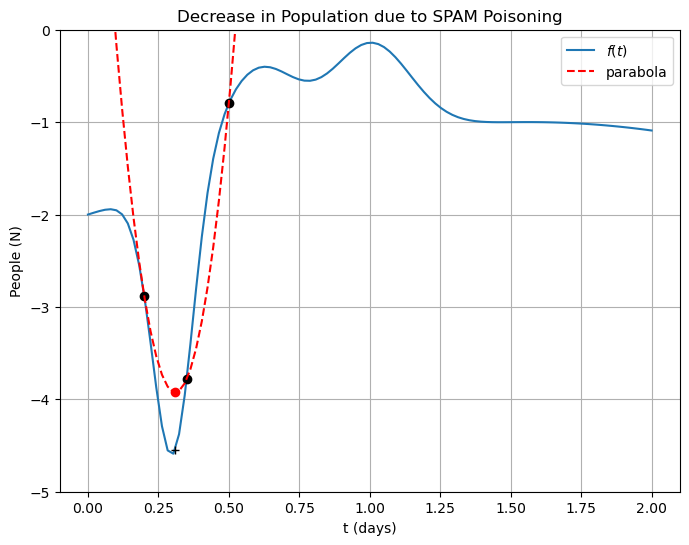
Rinse and repeat¶
MAX_STEPS = 100
TOLERANCE = 1e-4
x = numpy.array([x0, x1, (x0 + x1) / 2.0])
fig = plt.figure(figsize=(8, 6))
axes = fig.add_subplot(1, 1, 1)
axes.plot(t, f(t))
axes.set_xlabel("t (days)")
axes.set_ylabel("People (N)")
axes.set_title("Decrease in Population due to SPAM Poisoning")
axes.plot(x[0], f(x[0]), "ko")
axes.plot(x[1], f(x[1]), "ko")
success = False
for n in range(1, MAX_STEPS + 1):
axes.plot(x[2], f(x[2]), "ko")
poly = numpy.polyfit(x, f(x), 2)
axes.plot(t, poly[0] * t**2 + poly[1] * t + poly[2], "r--")
x[0] = x[1]
x[1] = x[2]
x[2] = -poly[1] / (2.0 * poly[0])
if numpy.abs(x[2] - x[1]) / numpy.abs(x[2]) < TOLERANCE:
success = True
break
if success:
print("Success!")
print(" t* = %s" % x[2])
print(" f(t*) = %s" % f(x[2]))
print(" number of steps = %s" % n)
else:
print("Reached maximum number of steps!")
axes.set_ylim((-5, 0.0))
axes.grid()
plt.show()Success!
t* = 0.295888307310968
f(t*) = -4.604285452397017
number of steps = 6
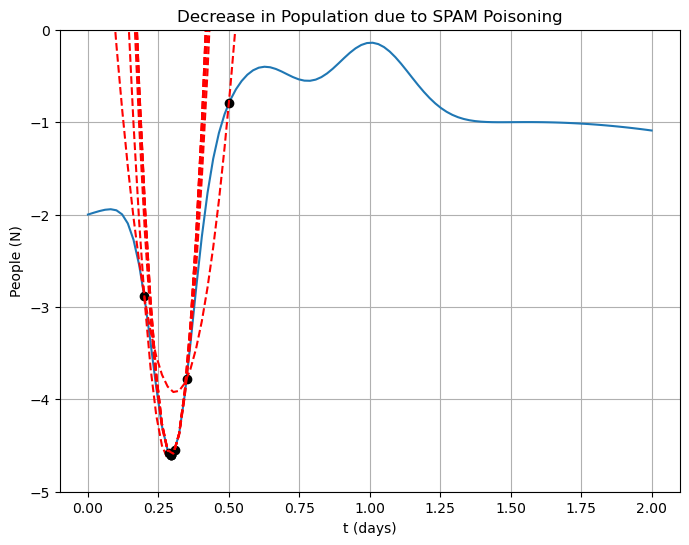
Some Code¶
def parabolic_interpolation(f, bracket, tol=1.0e-6):
"""uses repeated parabolic interpolation to refine a local minimum of a function f(x)
this routine uses numpy functions polyfit and polyval to fit and evaluate the quadratics
Parameters:
-----------
f: function f(x)
returns type: float
bracket: array
array [x0, x1] containing an initial bracket that contains a minimum
tolerance: float
Returns when relative error of last two iterates < tol
Returns:
--------
x: float
final estimate of the minima
x_array: numpy array
history of iteration points
Raises:
-------
Warning:
if number of iterations exceed MAX_STEPS
"""
MAX_STEPS = 100
x = numpy.zeros(3)
x[:2] = bracket
x[2] = (x[0] + x[1]) / 2.0
x_array = [x[2]]
for k in range(1, MAX_STEPS + 1):
poly = numpy.polyfit(x, f(x), 2)
x[0] = x[1]
x[1] = x[2]
x[2] = -poly[1] / (2.0 * poly[0])
x_array.append(x[2])
if numpy.abs(x[2] - x[1]) / numpy.abs(x[2]) < tol:
break
if k == MAX_STEPS:
warnings.warn("Maximum number of steps exceeded")
return x[2], numpy.array(x_array)set up problem¶
bracket = numpy.array([0.2, 0.5])
x, x_array = parabolic_interpolation(f, bracket, tol=1.0e-6)
print("Extremum f(x) = {}, at x = {}, N steps = {}".format(f(x), x, len(x_array)))Extremum f(x) = -3.0, at x = -1.570796326807591, N steps = 11
t = numpy.linspace(0, 2, 200)
fig = plt.figure(figsize=(8, 6))
axes = fig.add_subplot(1, 1, 1)
axes.plot(t, f(t))
axes.plot(x_array, f(x_array), "ro")
axes.plot(x, f(x), "go")
axes.set_xlabel("t (days)")
axes.set_ylabel("People (N)")
axes.set_title("Decrease in Population due to SPAM Poisoning")
axes.grid()
plt.show()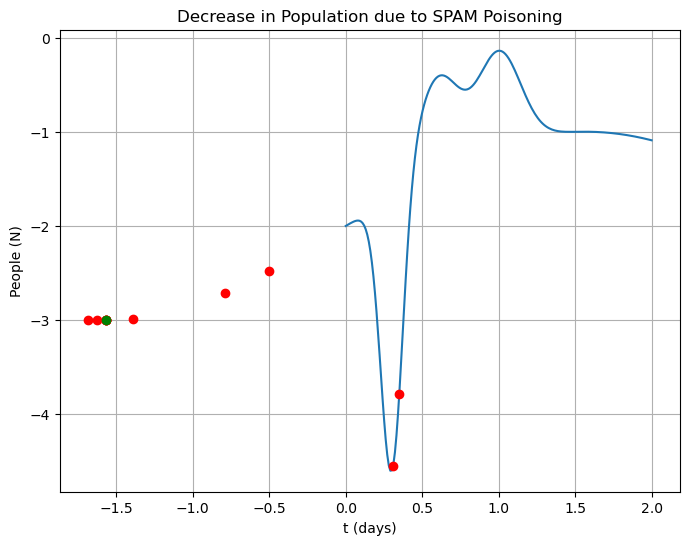
Bracketing Algorithm (Golden Section Search)¶
Given that is convex (concave) over an interval reduce the interval size until it brackets the minimum (maximum).
Note that we no longer have the help we had before so bracketing and doing bisection is a bit trickier in this case. In particular choosing your initial bracket is important!
Bracket Picking¶
Say we start with a bracket and pick two new points . We want to pick a new bracket that guarantees that the extrema exists in it. We then can pick this new bracket with the following rules:
If then we know the minimum is between and .
If then we know the minimum is between and .
f = lambda x: x**2
fig = plt.figure()
fig.set_figwidth(fig.get_figwidth() * 2)
fig.set_figheight(fig.get_figheight() * 2)
search_points = [-1.0, -0.5, 0.75, 1.0]
axes = fig.add_subplot(2, 2, 1)
x = numpy.linspace(search_points[0] - 0.1, search_points[-1] + 0.1, 100)
axes.plot(x, f(x), "b")
for i, point in enumerate(search_points):
axes.plot(point, f(point), "or")
axes.text(point + 0.05, f(point), str(i))
axes.plot(0, 0, "sk")
axes.set_xlim((search_points[0] - 0.1, search_points[-1] + 0.1))
axes.set_title("$f(x_1) < f(x_2) \Rightarrow [x_0, x_2]$")
search_points = [-1.0, -0.75, 0.5, 1.0]
axes = fig.add_subplot(2, 2, 2)
x = numpy.linspace(search_points[0] - 0.1, search_points[-1] + 0.1, 100)
axes.plot(x, f(x), "b")
for i, point in enumerate(search_points):
axes.plot(point, f(point), "or")
axes.text(point + 0.05, f(point), str(i))
axes.plot(0, 0, "sk")
axes.set_xlim((search_points[0] - 0.1, search_points[-1] + 0.1))
axes.set_title("$f(x_1) > f(x_2) \Rightarrow [x_1, x_3]$")
search_points = [-1.0, 0.25, 0.75, 1.0]
axes = fig.add_subplot(2, 2, 3)
x = numpy.linspace(search_points[0] - 0.1, search_points[-1] + 0.1, 100)
axes.plot(x, f(x), "b")
for i, point in enumerate(search_points):
axes.plot(point, f(point), "or")
axes.text(point + 0.05, f(point), str(i))
axes.plot(0, 0, "sk")
axes.set_xlim((search_points[0] - 0.1, search_points[-1] + 0.1))
axes.set_title("$f(x_1) < f(x_2) \Rightarrow [x_0, x_2]$")
search_points = [-1.0, -0.75, -0.25, 1.0]
axes = fig.add_subplot(2, 2, 4)
x = numpy.linspace(search_points[0] - 0.1, search_points[-1] + 0.1, 100)
axes.plot(x, f(x), "b")
for i, point in enumerate(search_points):
axes.plot(point, f(point), "or")
axes.text(point + 0.05, f(point), str(i))
axes.plot(0, 0, "sk")
axes.set_xlim((search_points[0] - 0.1, search_points[-1] + 0.1))
axes.set_title("$f(x_1) > f(x_2) \Rightarrow [x_1, x_3]$")
plt.show()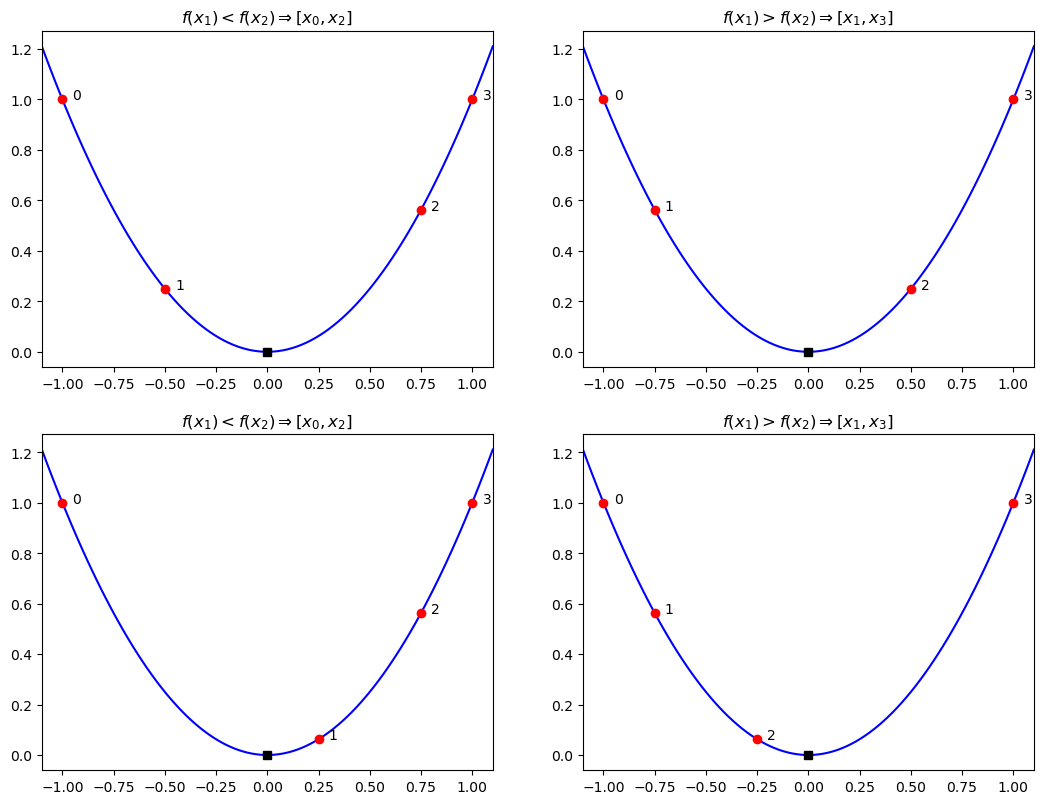
Picking Brackets and Points¶
Again say we have a bracket and suppose we have two new search points and that separates into two new overlapping brackets.
Define: the length of the line segments in the interval \begin{aligned} a &= x_1 - x_0, \ b &= x_2 - x_1,\ c &= x_3 - x_2 \ \end{aligned} and the total bracket length \begin{aligned} d &= x_3 - x_0. \ \end{aligned}
f = lambda x: (x - 0.25) ** 2 + 0.5
phi = (numpy.sqrt(5.0) - 1.0) / 2.0
x = [-1.0, None, None, 1.0]
x[1] = x[3] - phi * (x[3] - x[0])
x[2] = x[0] + phi * (x[3] - x[0])
fig = plt.figure(figsize=(8, 6))
axes = fig.add_subplot(1, 1, 1)
t = numpy.linspace(-2.0, 2.0, 100)
axes.plot(t, f(t), "k")
# First set of intervals
axes.plot([x[0], x[1]], [0.0, 0.0], "g", label="a")
axes.plot([x[1], x[2]], [0.0, 0.0], "r", label="b")
axes.plot([x[2], x[3]], [0.0, 0.0], "b", label="c")
axes.plot([x[0], x[3]], [2.5, 2.5], "c", label="d")
axes.plot([x[0], x[0]], [0.0, f(x[0])], "g--")
axes.plot([x[1], x[1]], [0.0, f(x[1])], "g--")
axes.plot([x[1], x[1]], [0.0, f(x[1])], "r--")
axes.plot([x[2], x[2]], [0.0, f(x[2])], "r--")
axes.plot([x[2], x[2]], [0.0, f(x[2])], "b--")
axes.plot([x[3], x[3]], [0.0, f(x[3])], "b--")
axes.plot([x[0], x[0]], [2.5, f(x[0])], "c--")
axes.plot([x[3], x[3]], [2.5, f(x[3])], "c--")
points = [
(x[0] + x[1]) / 2.0,
(x[1] + x[2]) / 2.0,
(x[2] + x[3]) / 2.0,
(x[0] + x[3]) / 2.0,
]
y = [0.0, 0.0, 0.0, 2.5]
labels = ["a", "b", "c", "d"]
for n, point in enumerate(points):
axes.text(point, y[n] + 0.1, labels[n], fontsize=15)
for n, point in enumerate(x):
axes.plot(point, f(point), "ok")
axes.text(point, f(point) + 0.1, n, fontsize="15")
axes.set_xlim((search_points[0] - 0.1, search_points[-1] + 0.1))
axes.set_ylim((-1.0, 3.0))
plt.show()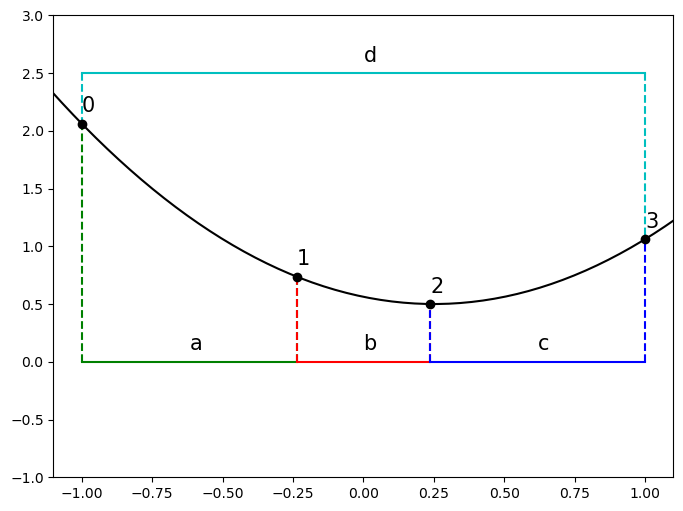
For Golden Section Search we require two conditions:
The two new possible brackets are of equal length. i.e or
or simply
f = lambda x: (x - 0.25) ** 2 + 0.5
phi = (numpy.sqrt(5.0) - 1.0) / 2.0
x = [-1.0, None, None, 1.0]
x[1] = x[3] - phi * (x[3] - x[0])
x[2] = x[0] + phi * (x[3] - x[0])
fig = plt.figure(figsize=(8, 6))
axes = fig.add_subplot(1, 1, 1)
t = numpy.linspace(-2.0, 2.0, 100)
axes.plot(t, f(t), "k")
# First set of intervals
axes.plot([x[0], x[1]], [0.0, 0.0], "g", label="a")
axes.plot([x[1], x[2]], [0.0, 0.0], "r", label="b")
axes.plot([x[2], x[3]], [0.0, 0.0], "b", label="c")
axes.plot([x[0], x[3]], [2.5, 2.5], "c", label="d")
axes.plot([x[0], x[0]], [0.0, f(x[0])], "g--")
axes.plot([x[1], x[1]], [0.0, f(x[1])], "g--")
axes.plot([x[1], x[1]], [0.0, f(x[1])], "r--")
axes.plot([x[2], x[2]], [0.0, f(x[2])], "r--")
axes.plot([x[2], x[2]], [0.0, f(x[2])], "b--")
axes.plot([x[3], x[3]], [0.0, f(x[3])], "b--")
axes.plot([x[0], x[0]], [2.5, f(x[0])], "c--")
axes.plot([x[3], x[3]], [2.5, f(x[3])], "c--")
points = [
(x[0] + x[1]) / 2.0,
(x[1] + x[2]) / 2.0,
(x[2] + x[3]) / 2.0,
(x[0] + x[3]) / 2.0,
]
y = [0.0, 0.0, 0.0, 2.5]
labels = ["a", "b", "c", "d"]
for n, point in enumerate(points):
axes.text(point, y[n] + 0.1, labels[n], fontsize=15)
for n, point in enumerate(x):
axes.plot(point, f(point), "ok")
axes.text(point, f(point) + 0.1, n, fontsize="15")
axes.set_xlim((search_points[0] - 0.1, search_points[-1] + 0.1))
axes.set_ylim((-1.0, 3.0))
plt.show()The ratio of segment lengths is the same for every level of recursion so the problem is self-similar i.e.
These two requirements will allow maximum reuse of previous points and require adding only one new point at each iteration.
f = lambda x: (x - 0.25) ** 2 + 0.5
phi = (numpy.sqrt(5.0) - 1.0) / 2.0
x = [-1.0, None, None, 1.0]
x[1] = x[3] - phi * (x[3] - x[0])
x[2] = x[0] + phi * (x[3] - x[0])
fig = plt.figure()
fig.set_figwidth(fig.get_figwidth() * 2)
axes = []
axes.append(fig.add_subplot(1, 2, 1))
axes.append(fig.add_subplot(1, 2, 2))
t = numpy.linspace(-2.0, 2.0, 100)
for i in range(2):
axes[i].plot(t, f(t), "k")
# First set of intervals
axes[i].plot([x[0], x[2]], [0.0, 0.0], "g")
axes[i].plot([x[1], x[3]], [-0.2, -0.2], "r")
axes[i].plot([x[0], x[0]], [0.0, f(x[0])], "g--")
axes[i].plot([x[2], x[2]], [0.0, f(x[2])], "g--")
axes[i].plot([x[1], x[1]], [-0.2, f(x[1])], "r--")
axes[i].plot([x[3], x[3]], [-0.2, f(x[3])], "r--")
for n, point in enumerate(x):
axes[i].plot(point, f(point), "ok")
axes[i].text(point, f(point) + 0.1, n, fontsize="15")
axes[i].set_xlim((search_points[0] - 0.1, search_points[-1] + 0.1))
axes[i].set_ylim((-1.0, 3.0))
# Left new interval
x_new = [x[0], None, x[1], x[2]]
x_new[1] = phi * (x[1] - x[0]) + x[0]
# axes[0].plot([x_new[0], x_new[2]], [1.5, 1.5], 'b')
# axes[0].plot([x_new[1], x_new[3]], [1.75, 1.75], 'c')
# axes[0].plot([x_new[0], x_new[0]], [1.5, f(x_new[0])], 'b--')
# axes[0].plot([x_new[2], x_new[2]], [1.5, f(x_new[2])], 'b--')
# axes[0].plot([x_new[1], x_new[1]], [1.75, f(x_new[1])], 'c--')
# axes[0].plot([x_new[3], x_new[3]], [1.75, f(x_new[3])], 'c--')
axes[0].plot(x_new[1], f(x_new[1]), "ko")
axes[0].text(x_new[1], f(x_new[1]) + 0.1, "*", fontsize="15")
for i in range(4):
axes[0].text(x_new[i], -0.5, i, color="g", fontsize="15")
# Right new interval
x_new = [x[1], x[2], None, x[3]]
x_new[2] = (x[2] - x[1]) * phi + x[2]
# axes[1].plot([x_new[0], x_new[2]], [1.25, 1.25], 'b')
# axes[1].plot([x_new[1], x_new[3]], [1.5, 1.5], 'c')
# axes[1].plot([x_new[0], x_new[0]], [1.25, f(x_new[0])], 'b--')
# axes[1].plot([x_new[2], x_new[2]], [1.25, f(x_new[2])], 'b--')
# axes[1].plot([x_new[1], x_new[1]], [1.5, f(x_new[2])], 'c--')
# axes[1].plot([x_new[3], x_new[3]], [1.5, f(x_new[3])], 'c--')
axes[1].plot(x_new[2], f(x_new[2]), "ko")
axes[1].text(x_new[2], f(x_new[2]) + 0.1, "*", fontsize="15")
for i in range(4):
axes[1].text(x_new[i], -0.5, i, color="r", fontsize="15")
axes[0].set_title("Choose left bracket", fontsize=18)
axes[1].set_title("Choose right bracket", fontsize=18)
plt.show()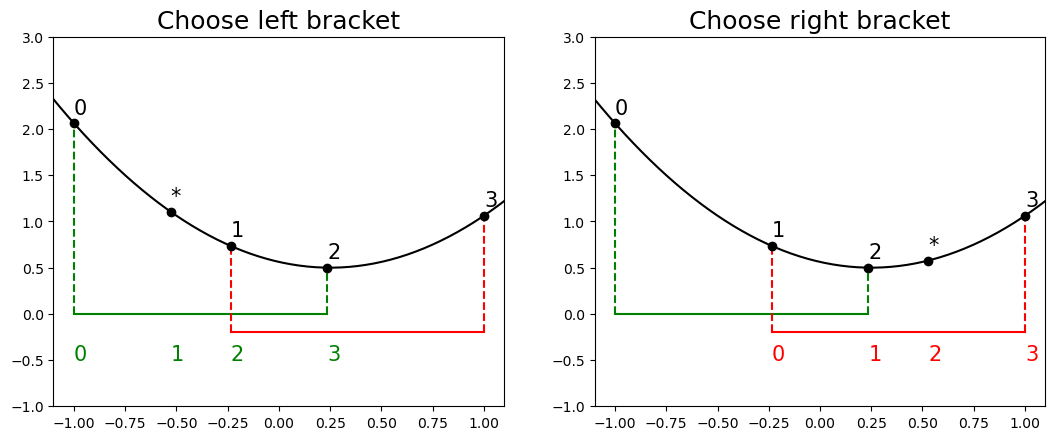
As the first rule implies that , we can substitute into the second rule to yield
or inverting and rearranging
if we let the ratio , then
has a single positive root for
where is related to the “golden ratio” (which in most definitions is given by , but either work as )
Subsequent proportionality implies that the distances between the 4 points at one iteration is proportional to the next. We can now use all of our information to find the points and given any overall bracket
Given , , and the known width of the bracket it follows that
or
by the rather special properties of .
We could use this result immediately to find
f = lambda x: (x - 0.25) ** 2 + 0.5
phi = (numpy.sqrt(5.0) - 1.0) / 2.0
x = [-1.0, None, None, 1.0]
x[1] = x[3] - phi * (x[3] - x[0])
x[2] = x[0] + phi * (x[3] - x[0])
fig = plt.figure(figsize=(8, 6))
axes = fig.add_subplot(1, 1, 1)
t = numpy.linspace(-2.0, 2.0, 100)
axes.plot(t, f(t), "k")
# First set of intervals
axes.plot([x[0], x[1]], [0.0, 0.0], "g", label="a")
axes.plot([x[1], x[2]], [0.0, 0.0], "r", label="b")
axes.plot([x[2], x[3]], [0.0, 0.0], "b", label="c")
axes.plot([x[0], x[3]], [2.5, 2.5], "c", label="d")
axes.plot([x[0], x[0]], [0.0, f(x[0])], "g--")
axes.plot([x[1], x[1]], [0.0, f(x[1])], "g--")
axes.plot([x[1], x[1]], [0.0, f(x[1])], "r--")
axes.plot([x[2], x[2]], [0.0, f(x[2])], "r--")
axes.plot([x[2], x[2]], [0.0, f(x[2])], "b--")
axes.plot([x[3], x[3]], [0.0, f(x[3])], "b--")
axes.plot([x[0], x[0]], [2.5, f(x[0])], "c--")
axes.plot([x[3], x[3]], [2.5, f(x[3])], "c--")
points = [
(x[0] + x[1]) / 2.0,
(x[1] + x[2]) / 2.0,
(x[2] + x[3]) / 2.0,
(x[0] + x[3]) / 2.0,
]
y = [0.0, 0.0, 0.0, 2.5]
labels = ["a", "b", "c", "d"]
for n, point in enumerate(points):
axes.text(point, y[n] + 0.1, labels[n], fontsize=15)
for n, point in enumerate(x):
axes.plot(point, f(point), "ok")
axes.text(point, f(point) + 0.1, n, fontsize="15")
axes.set_xlim((search_points[0] - 0.1, search_points[-1] + 0.1))
axes.set_ylim((-1.0, 3.0))
plt.show()Algorithm¶
Initialize bracket
Initialize points and
Loop
Evaluate and
If then we pick the left interval for the next iteration
and otherwise pick the right interval
Check size of bracket for convergence
TOLERANCEcalculate the appropriate new point ( on left, on right)
def golden_section(f, bracket, tol=1.0e-6):
"""uses golden section search to refine a local minimum of a function f(x)
this routine uses numpy functions polyfit and polyval to fit and evaluate the quadratics
Parameters:
-----------
f: function f(x)
returns type: float
bracket: array
array [x0, x3] containing an initial bracket that contains a minimum
tolerance: float
Returns when | x3 - x0 | < tol
Returns:
--------
x: float
final estimate of the midpoint of the bracket
x_array: numpy array
history of midpoint of each bracket
Raises:
-------
ValueError:
If initial bracket is < tol or doesn't appear to have any interior points
that are less than the outer points
Warning:
if number of iterations exceed MAX_STEPS
"""
MAX_STEPS = 100
phi = (numpy.sqrt(5.0) - 1.0) / 2.0
x = [bracket[0], None, None, bracket[1]]
delta_x = x[3] - x[0]
x[1] = x[3] - phi * delta_x
x[2] = x[0] + phi * delta_x
# check for initial bracket
fx = f(numpy.array(x))
bracket_min = min(fx[0], fx[3])
if fx[1] > bracket_min and fx[2] > bracket_min:
raise ValueError("interval does not appear to include a minimum")
elif delta_x < tol:
raise ValueError("interval is already smaller than tol")
x_mid = (x[3] + x[0]) / 2.0
x_array = [x_mid]
for k in range(1, MAX_STEPS + 1):
f_1 = f(x[1])
f_2 = f(x[2])
if f_1 < f_2:
# Pick the left bracket
x_new = [x[0], None, x[1], x[2]]
delta_x = x_new[3] - x_new[0]
x_new[1] = x_new[3] - phi * delta_x
else:
# Pick the right bracket
x_new = [x[1], x[2], None, x[3]]
delta_x = x_new[3] - x_new[0]
x_new[2] = x_new[0] + phi * delta_x
x = x_new
x_array.append((x[3] + x[0]) / 2.0)
if numpy.abs(x[3] - x[0]) < tol:
break
if k == MAX_STEPS:
warnings.warn("Maximum number of steps exceeded")
return x_array[-1], numpy.array(x_array)def f(t):
"""Simple function for minimization demos"""
return (
-3.0 * numpy.exp(-((t - 0.3) ** 2) / (0.1) ** 2)
+ numpy.exp(-((t - 0.6) ** 2) / (0.2) ** 2)
+ numpy.exp(-((t - 1.0) ** 2) / (0.2) ** 2)
+ numpy.sin(t)
- 2.0
)x, x_array = golden_section(f, [0.2, 0.5], 1.0e-4)
print("t* = {}, f(t*) = {}, N steps = {}".format(x, f(x), len(x_array) - 1))t* = 0.29588198925376136, f(t*) = -4.604285440148672, N steps = 17
t = numpy.linspace(0, 2, 200)
fig = plt.figure(figsize=(8, 6))
axes = fig.add_subplot(1, 1, 1)
axes.plot(t, f(t))
axes.grid()
axes.set_xlabel("t (days)")
axes.set_ylabel("People (N)")
axes.set_title("Decrease in Population due to SPAM Poisoning")
axes.plot(x_array, f(x_array), "ko")
axes.plot(x_array[0], f(x_array[0]), "ro")
axes.plot(x_array[-1], f(x_array[-1]), "go")
plt.show()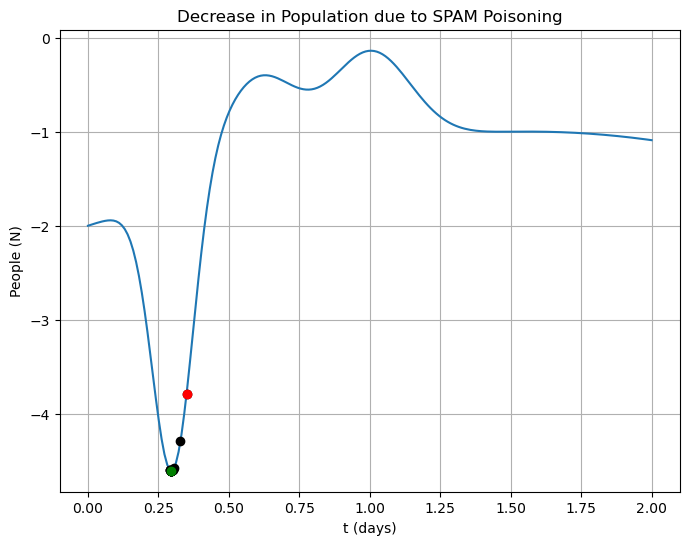
Scipy Optimization¶
Scipy contains a lot of methods for optimization. But a convenenient interface for minimization of functions of a single variable is scipy.optimize.minimize_scalar
For optimization or constrained optimization for functions of more than one variable, see
scipy.optimized.minimize
from scipy.optimize import minimize_scalar
# minimize_scalar?Try some different methods¶
sol = minimize_scalar(f, bracket=(0.2, 0.25, 0.5), method="golden")
print(sol) message:
Optimization terminated successfully;
The returned value satisfies the termination criteria
(using xtol = 1.4901161193847656e-08 )
success: True
fun: -4.604285452397025
x: 0.29588830308853215
nit: 37
nfev: 42
sol = minimize_scalar(f, method="brent", bracket=(0.2, 0.25, 0.5))
print(sol) message:
Optimization terminated successfully;
The returned value satisfies the termination criteria
(using xtol = 1.48e-08 )
success: True
fun: -4.604285452397025
x: 0.2958883029740597
nit: 9
nfev: 12
sol = minimize_scalar(f, bounds=(0.0, 0.5), method="bounded")
print(sol) message: Solution found.
success: True
status: 0
fun: -4.604285452396983
x: 0.29588831409143207
nit: 9
nfev: 9